Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
- Scaling the amount of compute used for RL during training
- Scaling the amount of compute used for inference during deployment
We can see (1) as training the AI in more effective reasoning techniques and (2) as allowing the model to think for longer. I’ll call the first RL-scaling, and the second inference-scaling. Both new kinds of scaling were present all the way back in OpenAI’s announcement of their first reasoning model, o1, when they showed this famous chart:
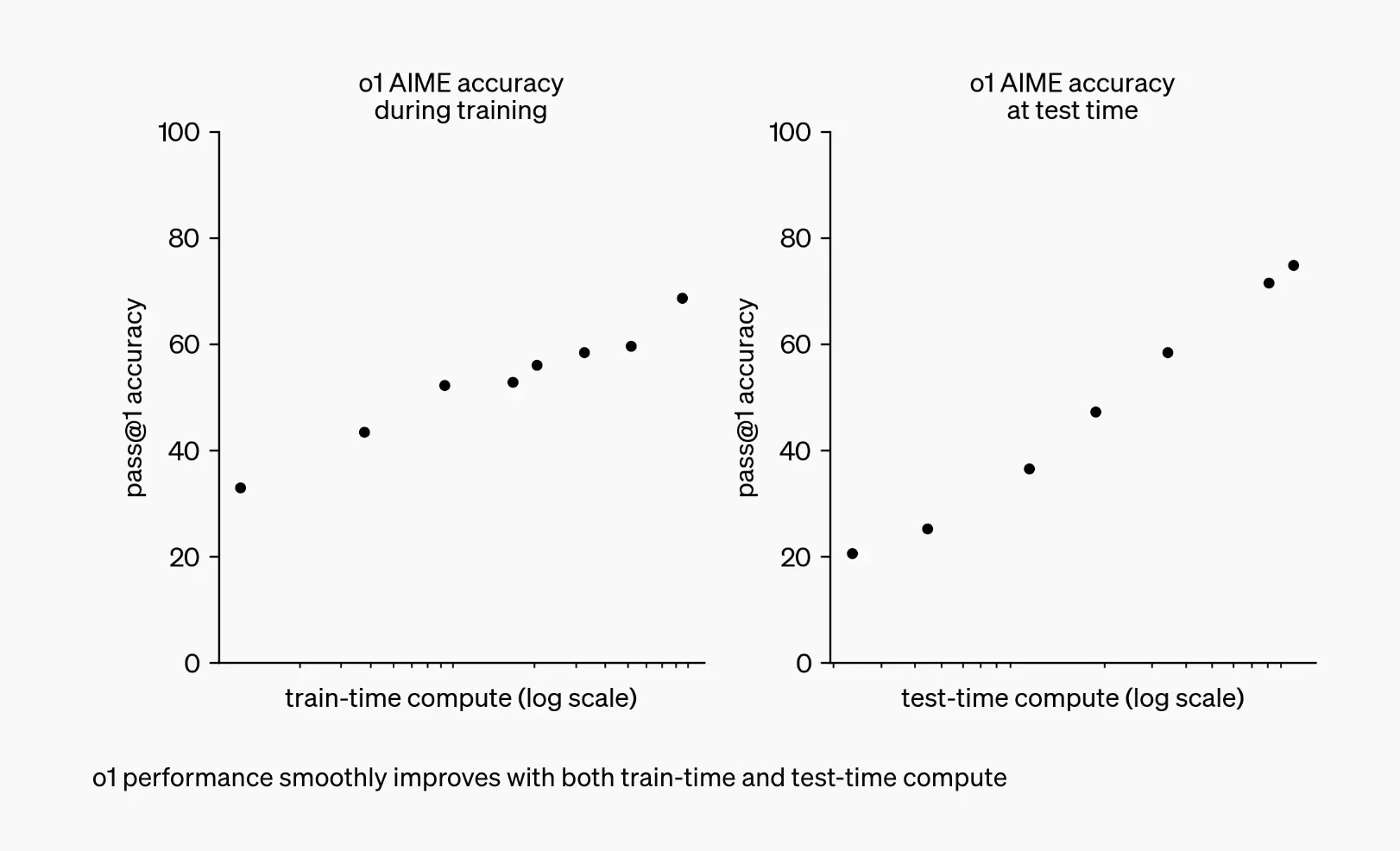
I’ve previously shown that in the initial move from a base-model to a reasoning model, most of the performance gain came from unlocking the inference-scaling. The RL training did provide a notable boost to performance, even holding the number of tokens in the chain of thought fixed. You can see this RL boost in the chart below as the small blue arrow on the left that takes the base model up to the trend-line for the reasoning model. But this RL also unlocked the ability to productively use much longer chains of thought (~30x longer in this example). And these longer chains of thought contributed a much larger boost.
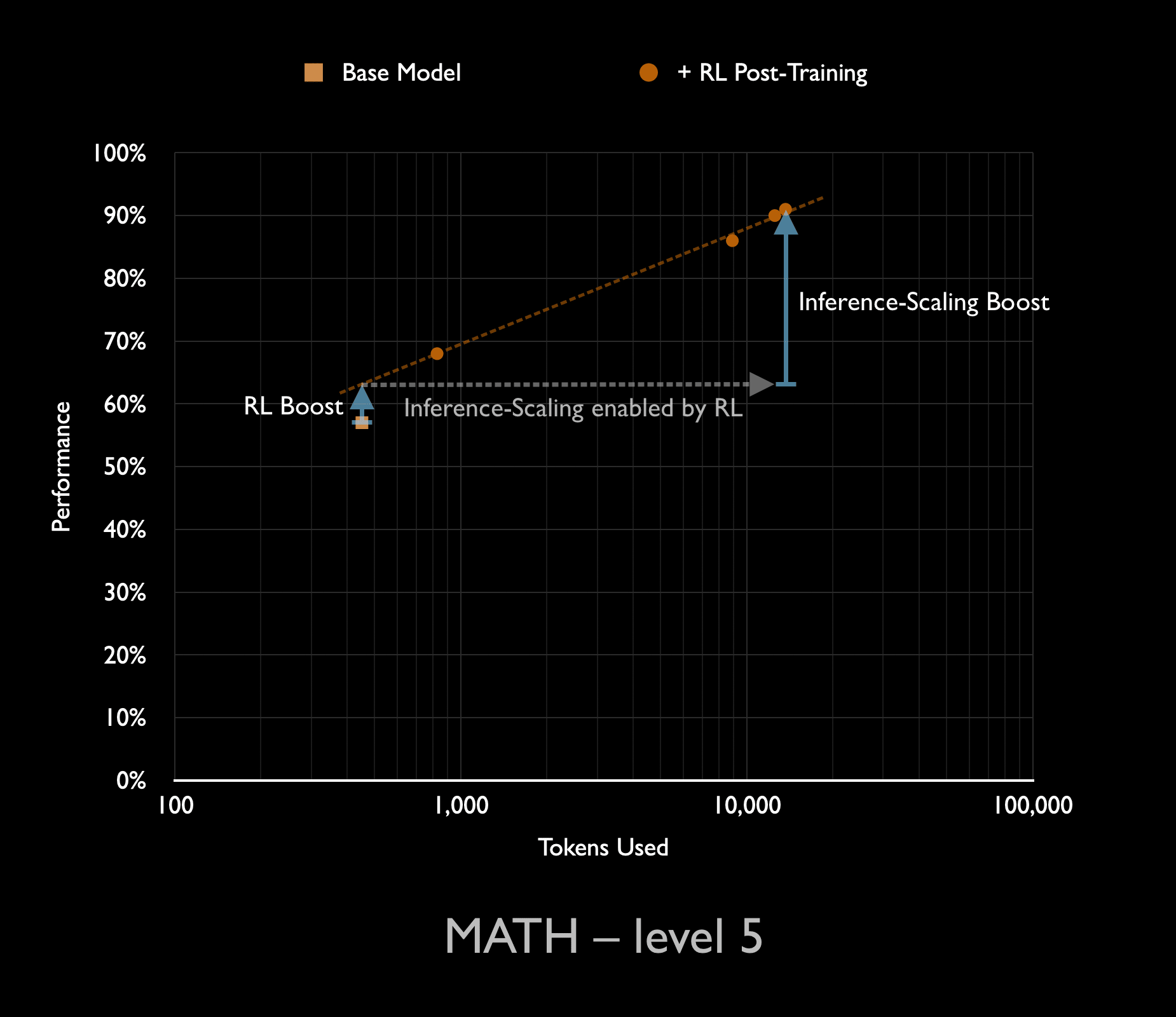
The question of where these capability gains come from is important because scaling up the inference compute has very different implications than scaling up the training compute. In this first round of reasoning models, they were trained with a very small amount of RL compute compared to the compute used in pre-training, meaning that the total cost of training was something like 1.01x higher than the base-model. But if most of the headline performance results require 30x as much inference compute, then the costs of deploying the those capabilities is 30x higher. Since frontier AI developers are already spending more money deploying their models than they did training them, multiplying those costs by 30x is a big deal. Moreover, these are costs that have to be paid every time you want to use the model at this level of capability, so can’t be made up in volume.
But that was just the initial application of RL to LLMs. What happens as companies create more advanced reasoning models, using more RL?
The seeds of the answer can be found all the way back in that original o1 chart.
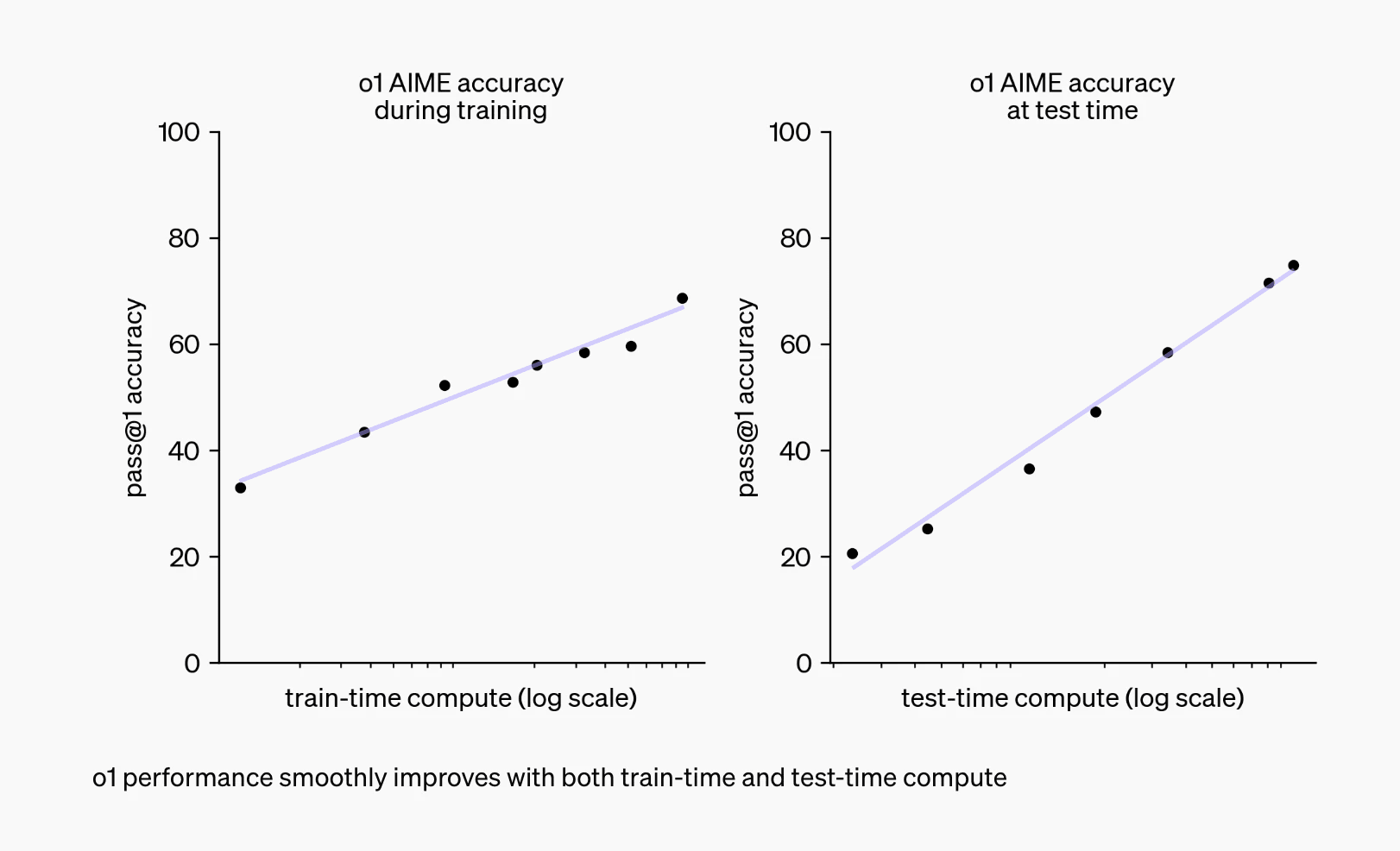
The chart shows steady improvements for both RL-scaling and inference-scaling, but they are not the same. Both graphs have the same y-axis and (despite the numbers being removed from the x-axis) we can see that they are both on a logarithmic x-axis covering almost exactly two orders of magnitude of scaling (100x). In both cases, the datapoints lie on a relatively straight line, which is presumably the central part of a larger S-curve. However, the slope of the RL-scaling graph (on the left) is almost exactly half that of the slope of the inference-scaling graph (on the right). When the x-axis is logarithmic, this has dramatic consequences.
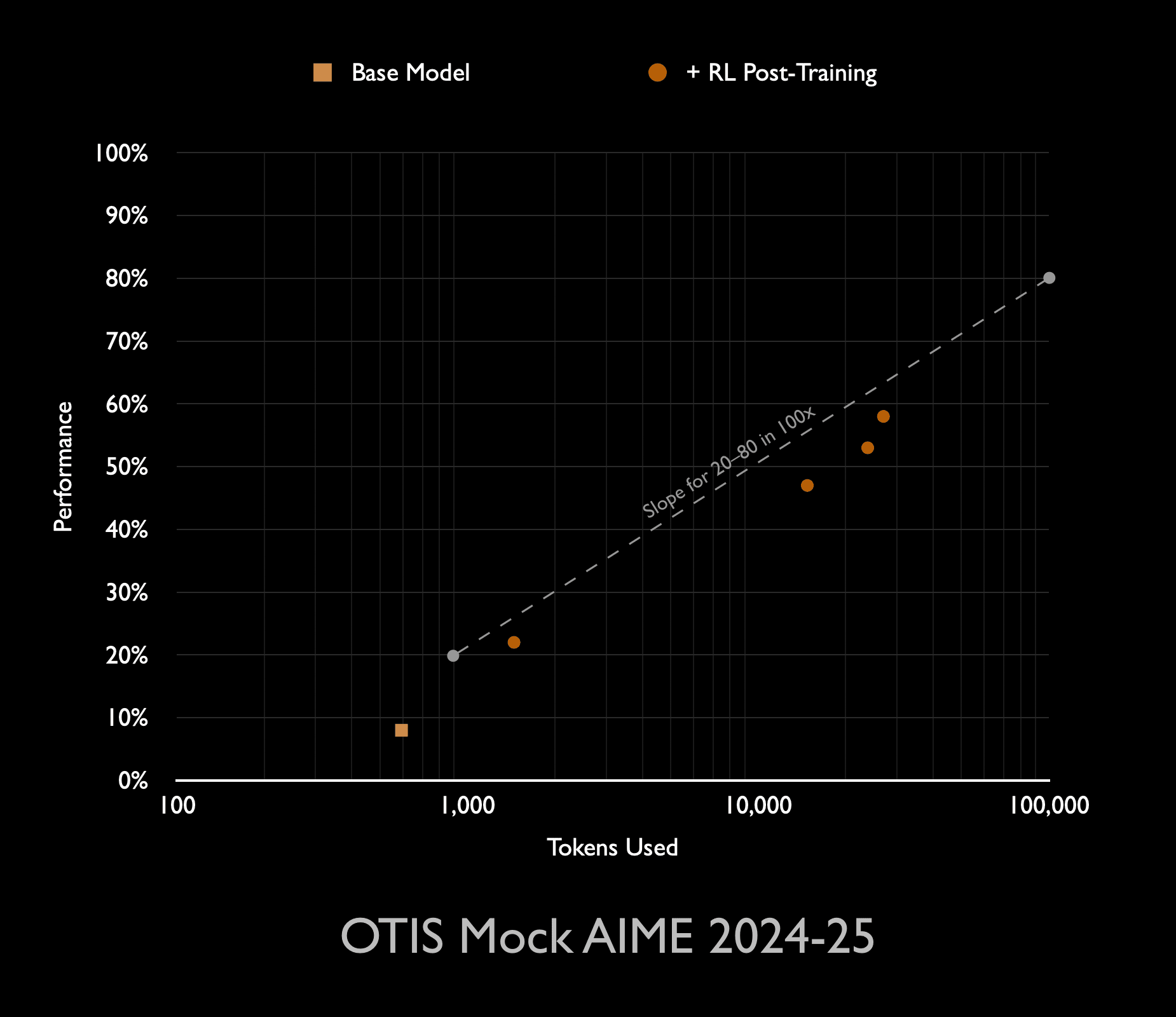
The graph on the right shows that scaling inference-compute by 100x is enough to drive performance from roughly 20% to 80% on the AIME benchmark. This is pretty typical for inference scaling, where quite a variety of different models and benchmarks see performance improve from 20% to 80% when inference is scaled by 100x.
For instance, this is what was found with Anthropic’s first reasoning model (Sonnet 3.7) on another AIME benchmark, with almost exactly the same scaling behaviour:
And ability on the ARC-AGI 1 benchmark also scales in a similar way for many of OpenAI’s different reasoning models:
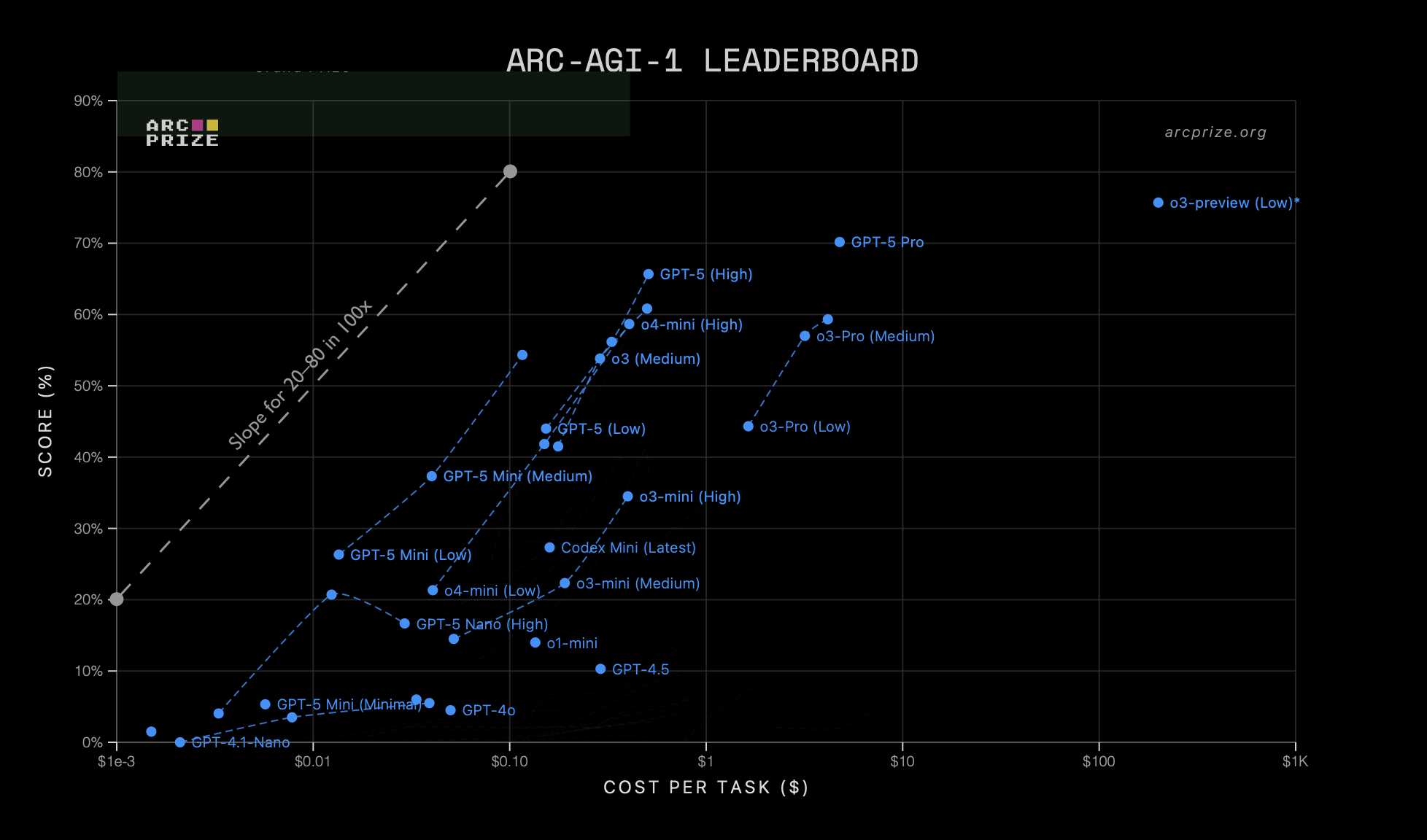
We don’t always see this scaling behaviour for inference: some combinations of LLM, inference-scaling technique, and benchmark see the performance plateau below 80% or exhibit a different slope (often worse). But this climb from 20 to 80 with 100x more inference compute is pretty common (especially for reasoning-intensive benchmarks) and almost certainly what is happening on that original o1 graph.
In contrast, the slope of the RL-scaling trend is half as large, which means that it requires twice as many orders of magnitude to achieve the exact same improvement in capabilities. Increasing the RL training compute by 100x as shown in the o1 chart only improved performance from about 33% to 66%. At that rate, going from 20 to 80 would require scaling up the RL training compute by 10,000x.
We can confirm this trend — and that it continued beyond o1 — by looking at the following graph from the o3 launch video (with a line added showing the slope corresponding to going from 20 to 80 in 10,000x):
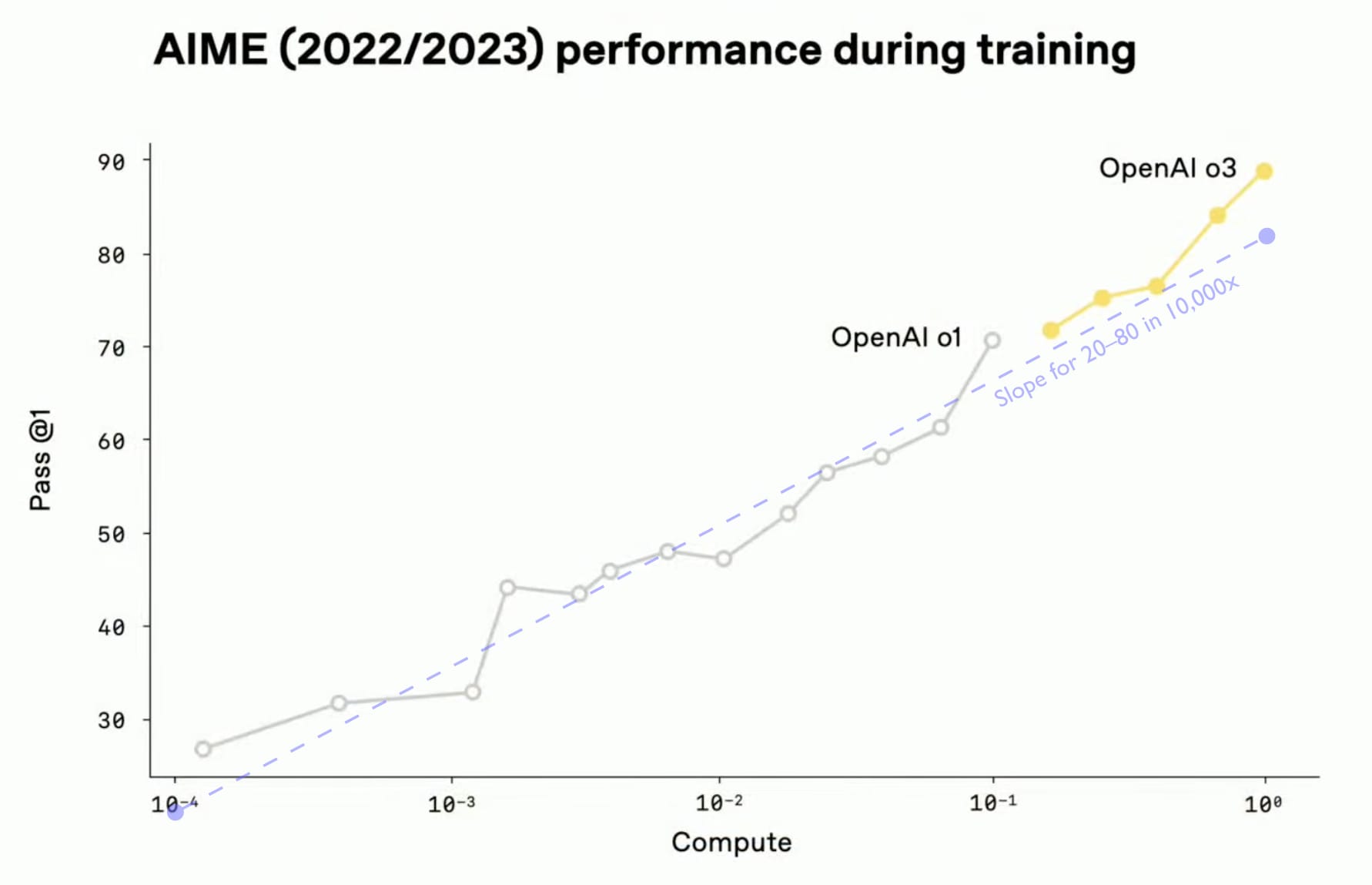
Using another version of the AIME benchmark, this shows o1’s training progress over 3 orders of magnitude and o3’s training over a further order of magnitude. In total, we see that scaling up the RL-training by 4 orders of magnitude takes the model from about 26% to 88%. This provides some confirmation for the rule-of-thumb that a 10,000x scale-up in RL training compute is required to improve this benchmark performance from 20 to 80.
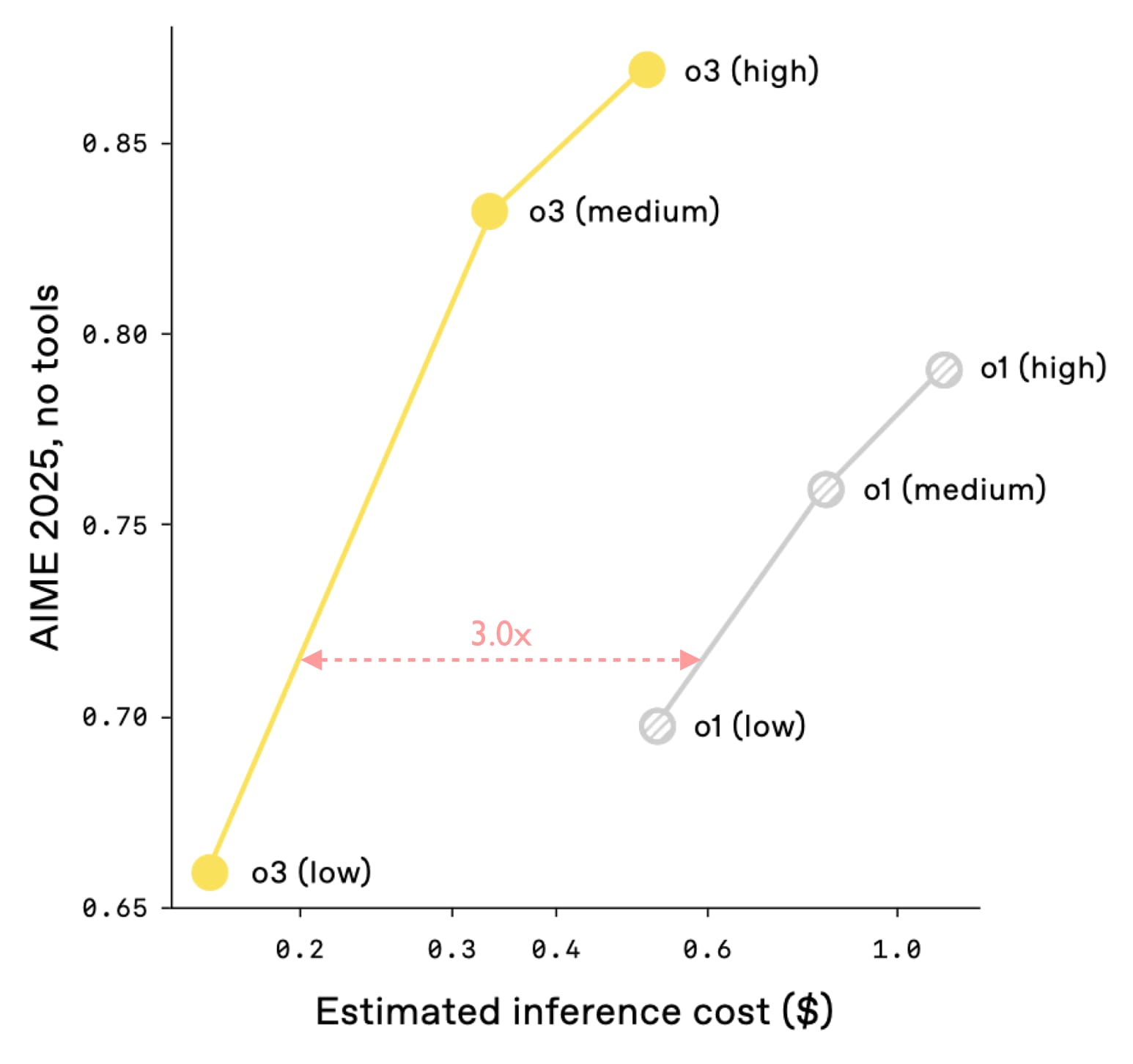
To my knowledge, OpenAI hasn’t provided RL-training curves for other benchmarks, but they do have charts comparing o1 with o3 and o3 with GPT-5 at different inference-scaling levels on several benchmarks. Given that o3 used about 10x as much RL training as o1, we’d expect the RL boost going from o1 to o3 to be worth about the same as the inference boost of giving o1 just half an order of magnitude more inference (~3x as many tokens). And this is indeed what one sees on their performance/token graph comparing the two:
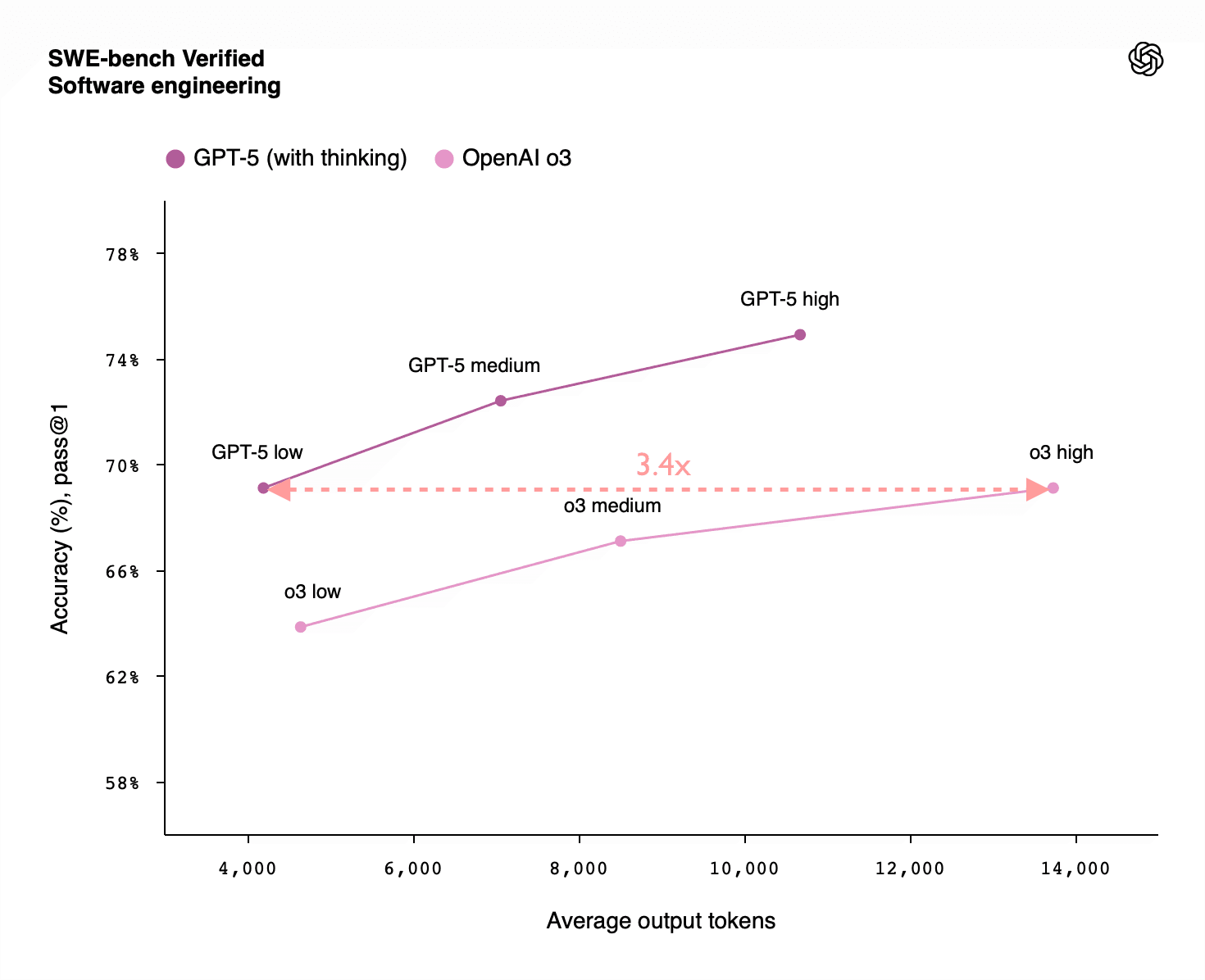
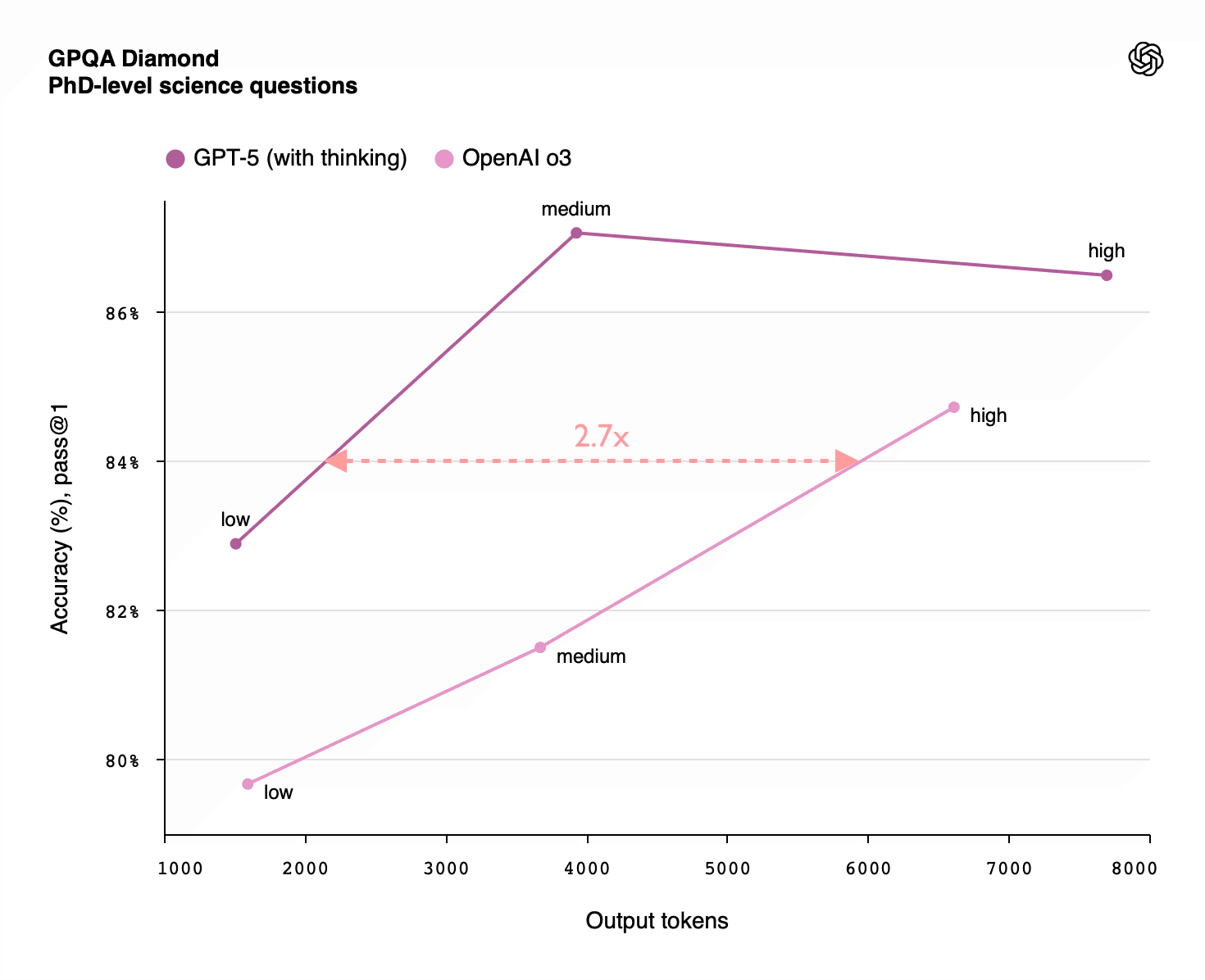
Similarly, o3 also requires about 3x as many tokens to match GPT-5 on the SWE-bench and GPQA Diamond benchmarks. This would fit the expected pattern of GPT-5 having been trained with a further 10x as much RL training compute as o3:
It is hard to verify that this trend holds for models from other companies, as this data on training curves for cutting-edge models is often treated as confidential. But the fact that other leading labs’ base models and reasoning models are roughly on par with OpenAI’s suggests none of them are scaling notably better than this.
So the evidence on RL-scaling and inference-scaling supports a general pattern:
- a 10x scaling of RL is required to get the same performance boost as a 3x scaling of inference
- a 10,000x scaling of RL is required to get the same performance boost as a 100x scaling of inference
In general, to get the same benefit from RL-scaling as from inference-scaling required twice as many orders of magnitude. That’s not good.
How do these compare to pre-training scaling?
The jumps from GPT-1 to 2 to 3 to 4 each involved scaling up the pre-training compute by about 100x. How much of the RL-scaling or inference-scaling would be required to give a similar boost? While I can’t say for sure, we can put together the clues we have and take an educated guess.
Jones (2021) and EpochAI both estimate that you need to scale-up inference by roughly 1,000x to reach the same capability you’d get from a 100x scale-up of training. And since the evidence from o1 and o3 suggests we need about twice as many orders of magnitude of RL-scaling compared with inference-scaling, this implies we need something like a 1,000,000x scale-up of total RL compute to give a boost similar to a GPT level.
This is breathtakingly inefficient scaling. But it fits with the extreme information inefficiency of RL training, which (compared to next-token-prediction) receives less than a ten-thousandth as much information to learn from per FLOP of training compute.
Yet despite the poor scaling behaviour, RL training has so far been a good deal. This is solely because the scaling of RL compute began from such a small base compared with the massive amount of pre-training compute invested in today’s models. While AI labs are reticent to share information about how much compute has actually been spent on RL (witness the removal of all numbers from the twin o1 scaling graphs), it is widely believed that even the 10,000x RL-scaling we saw for o3’s training still ended up using much less compute than the ~ FLOP spent on pre-training. This means that OpenAI (and their competitors) have effectively got those early gains from RL-training for free.
For example, if the 10x scaling of RL compute from o1 to o3 took them from a total of 1.01x the pre-training compute to 1.1x, then the 10x scale-up came at the price of a 1.1x scale-up in overall training costs. If that gives the same performance boost as using 3x as many reasoning tokens (which would multiply all deployment costs of reasoning models by 3) then it is a great deal for a company that deploys its model so widely.
But this changes dramatically once RL-training reaches and then exceeds the size of the pre-training compute. In July 2025, xAI’s Grok 4 launch video included a chart suggesting that they had reached this level (where pre-training compute is shown in white and RL-training compute in orange):
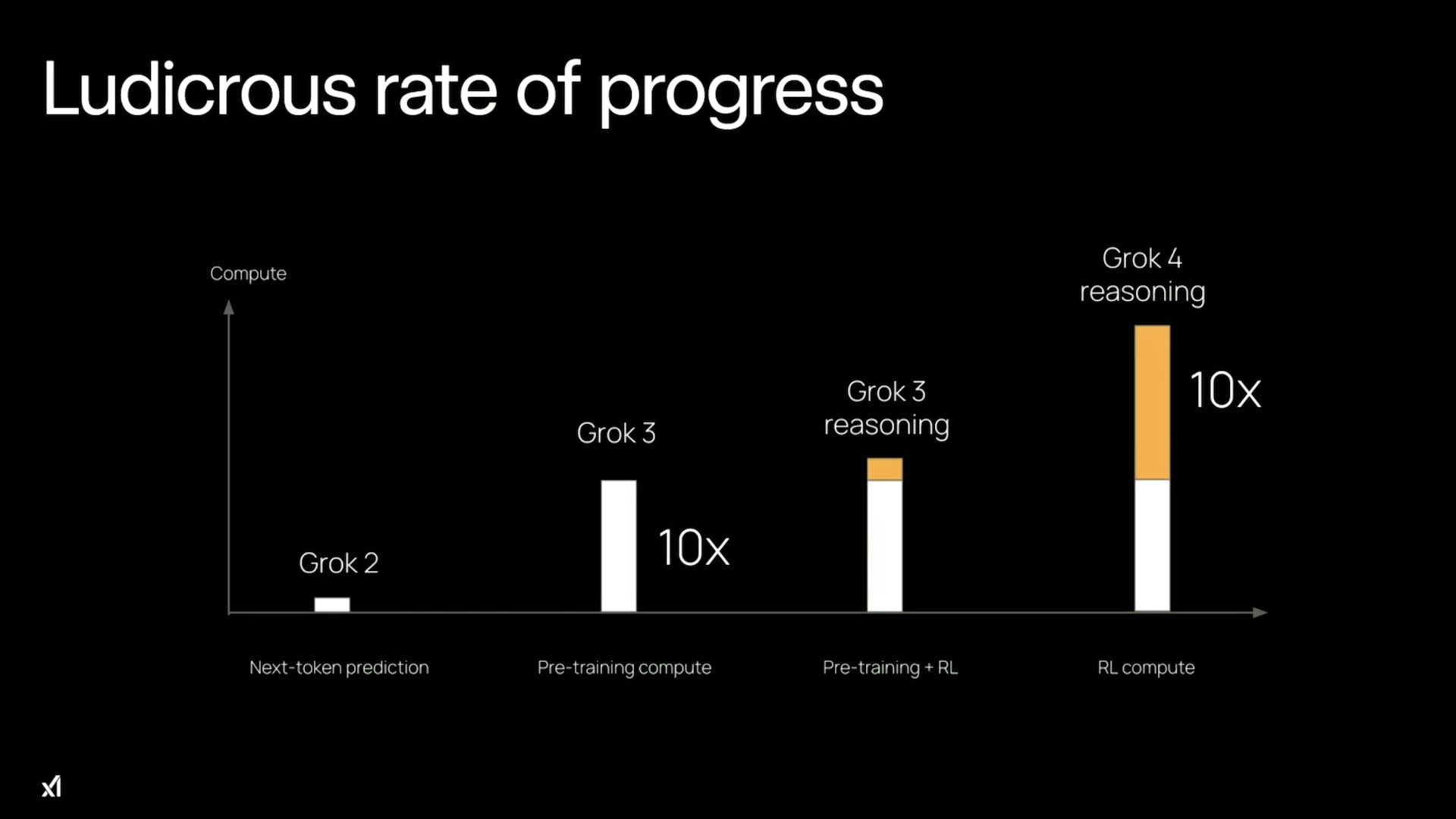
Scaling RL by another 10x beyond this point increases the total training compute by 5.5x, and beyond that it is basically the full 10x increase to all training costs. So this is the point where the fact that they get much less for a 10x scale-up of RL compute compared with 10x scale-ups in pre-training or inference really bites. I estimate that at the time of writing (Oct 2025), we’ve already seen something like a 1,000,000x scale-up in RL training and it required ≤2x the total training cost. But the next 1,000,000x scale-up would require 1,000,000x the total training cost, which is not possible in the foreseeable future.
Grok 4 was trained on 200,000 GPUs located in xAI’s vast Colossus datacenter. To achieve the equivalent of a GPT-level jump through RL would (according to the rough scaling relationships above) require 1,000,000x the total training compute. To put that in perspective, it would require replacing every GPU in their datacenter with 5 entirely new datacenters of the same size, then using 5 years worth of the entire world’s electricity production to train the model. So it looks infeasible for further scaling of RL-training compute to give even a single GPT-level boost.
I don’t think OpenAI, Google, or Anthropic have quite reached the point where RL training compute matches the pre-training compute. But they are probably not far off. So while we may see another jump in reasoning ability beyond GPT-5 by scaling RL training a further 10x, I think that is the end of the line for cheap RL-scaling.
Conclusion
The shift towards RL allowed the scaling era to continue even after pre-training scaling had stalled. It did so via two different mechanisms: scaling up the RL training compute and scaling up the inference compute.
Scaling RL training allowed the model to learn for itself how to achieve better performance. Unlike the imitation learning of next-token-prediction, RL training has a track record of allowing systems to burst through the human level — finding new ways of solving problems that go beyond its training data. But in the context of LLMs, it scales poorly. We’ve seen impressive gains, but these were only viable when starting from such a low base. We have reached the point where it is too expensive to go much further.
This leaves us with inference-scaling as the remaining form of compute-scaling. RL helped enable inference-scaling via longer chain of thought and, when it comes to LLMs, that may be its most important legacy. But inference-scaling has very different dynamics to scaling up the training compute. For one thing, it scales up the flow of ongoing costs instead of scaling the one-off training cost. This has many consequences for AI deployment, AI risk, and AI governance.
But perhaps more importantly, inference-scaling is really a way of improving capabilities by allowing the model more time to solve the problem, rather than by increasing its intelligence. Now that RL-training is nearing its effective limit, we may have lost the ability to effectively turn more compute into more intelligence.
First published on 20 October 2025
The Unjournal (unjournal.org) is considering commissioning this post for expert evaluation in our applied stream.
Looking for any feedback (here or privately) on whether this would be high-value, how to go about it (what particular issues/expertise), whether other research in this domain is higher value, etc.
I think the post makes a useful snapshot point: for some public “reasoning model vs base” comparisons, a large fraction of measured uplift shows up as increased inference-time deliberation.
But I don’t think that supports the stronger, extrapolative claim that “RL is extremely inefficient for frontier models” or that “recent gains are mostly inference” in a way that should generalize.
Two missing gears:
So I’d endorse a modest takeaway (“inference scaling is currently important”), but I’m skeptical of treating observed RLVR curves and one-generation decompositions as a stable law.
While I appreciate this work being done, it seems a very bad sign for our world/timeline that the very few people with both philosophy training and an interest in AI x-safety are using their time/talent to do forecasting (or other) work instead of solving philosophical problems in AI x-safety, with Daniel Kokotajlo being another prominent example.
This implies one of two things: Either they are miscalculating the best way to spend their time, which indicates bad reasoning or intuitions even among humanity's top philosophers (i.e., those who have at least realized the importance of AI x-risk and are trying to do something about it). Or they actually are the best people (in a comparative advantage sense) available to work on these other problems, in which case the world must be on fire, and they're having to delay working on extremely urgent problems that they were trained for, to put out even bigger fires.
(Cross-posted to LW and EAF.)
Why do you think this work has less value than solving philosophical problems in AI safety? If LLM scaling is sputtering out, isn't that important to know? In fact, isn't it a strong contender for the most important fact about AI that could be known right now?
I suppose you could ask why this work hasn't been done by somebody else already and that's a really good question. For instance, why didn't anyone doing equity research or AI journalism notice this already?
Among people who are highly concerned about near-term AGI, I don't really expect such insights to be surfaced. There is strong confirmation bias. People tend to look for confirmation that AGI is coming soon and not for evidence against. So, I'm not surprised that Toby Ord is the first person within effective altruism to notice this. Most people aren't looking. But this doesn't explain why equity research analysts, AI journalists, or others who are interested in LLM scaling (such as AI researchers or engineers not working for one of the major LLM companies and not bound by an NDA) missed this. I am surprised an academic philosopher is the first person to notice this! And kudos to him for that!
From the perspective of comparative advantage and counterfactual impact, this work does not seem to require philosophical training. It seems to be straightforward empirical research, that many people could do, besides the very few professionally trained AI-risk-concerned philosophers that humanity has.
To put it another way, I'm not sure that Toby was wrong to work on this, but if he was, it's because if he hadn't, then someone else with more comparative advantage for working on this problem (due to lacking training or talent for philosophy) would have done so shortly afterwards.
How shortly? We're discussing this in October 2025. What's the newest piece of data that Toby's analysis is dependent on? Maybe the Grok 4 chart from July 2025? Or possibly qualitative impressions from the GPT-5 launch in August 2025? Who else is doing high-quality analysis of this kind and publishing it, even using older data?
I guess I don't automatically buy the idea that even in a few months we'll see someone else independently go through the same reasoning steps as this post and independently come to the same conclusion. But there are plenty of people who could, in theory, do it and who are, in theory, motivated to do this kind of analysis and who also will probably not see this post (e.g. equity research analysts, journalists covering AI, AI researchers and engineers independent of LLM companies).
I certainly don't buy the idea that if Toby hadn't done this analysis, then someone else in effective altruism would have done it. I don't see anybody else in effective altruism doing similar analysis. (I chalk that up largely to confirmation bias.)
I appreciate you raising this Wei (and Yarrow's responses too). They both echoed a lot of my internal debate on this. I'm definitely not sure whether this is the best use of my time. At the moment, my research time is roughly evenly split between this thread of essays on AI scaling and more philosophical work connected to longtermism, existential risk and post-AGI governance. The former is much easier to demonstrate forward progress and there is more of a demand signal for it. The latter is harder to be sure it is on the right path and is in less demand. My suspicion is that it is generally more important though, and that demand/appreciation doesn't track importance very well.
It is puzzling to me too that no-one else was doing this kind of work on understanding scaling. I think I must be adding some rare ingredient, but I can't think of anything rare enough to really explain why no-one else got these results first. (People at the labs probably worked out a large fraction of this, but I still don't understand why the people not at the labs didn't.)
In addition to the general questions about which strand is more important, there are a few more considerations:
But I've often found your (Wei Dai's) comments over the last 15-or-so years to be interesting, unusual, and insightful. So I'll definitely take into account your expressed demand for more philosophical work and will look through those pages of philosophical questions you linked to.
Do you have any insights into why there are so few philosophers working in AI alignment, or closely with alignment researchers? (Amanda Askell is the only one I know.) Do you think this is actually a reasonable state of affairs (i.e., it's right or fine that almost no professional philosophers work directly as or with alignment researchers), or is this wrong/suboptimal, caused by some kind of cultural or structural problem? It's been 6 years since I wrote Problems in AI Alignment that philosophers could potentially contribute to and I've gotten a few comments from philosophers saying they found the list helpful or that they'll think about working on some of the problems, but I'm not aware of any concrete follow-ups.
If it is some kind of cultural or structural problem, it might be even higher leverage to work on solving that, instead of object level philosophical problems. I'd try to do this myself, but as an outsider to academic philosophy and also very far from any organizations who might potentially hire philosophers to work on AI alignment, it's hard for me to even observe what the problem might be.
Re 99% of academic philosophers, they are doing their own thing and have not heard of these possibilities and wouldn't be likely to move away from their existing areas if they had. Getting someone to change their life's work is not easy and usually requires hours of engagement to have a chance. It is especially hard to change what people work on in a field when you are outside that field.
A different question is about the much smaller number of philosophers who engage with EA and/or AI safety (there are maybe 50 of these). Some of these are working on some of those topics you mention. e.g. Will MacAskill and Joe Carlsmith have worked on several of these. I think some have given up philosophy to work on other things such as AI alignment. I've done occasional bits of work related to a few of these (e.g. here on dealing with infinities arising in decision theory and ethics without discounting) and also to other key philosophical questions that aren't on your list.
For such philosophers, I think it is a mixture of not having seen your list and not being convinced these are the best things that they each could be working on.
I was going to say something about lack of incentives, but I think it is also a lack of credible signals that the work is important, is deeply desired by others working in these fields, and would be used to inform deployments of AI. In my view, there isn't much desire for work like this from people in the field and they probably wouldn't use it to inform deployment unless a lot of effort is also added from the author to meet the right people, convince theme to spend the time to take it seriously etc.
Right, I know about Will MacAskill, Joe Carlsmith, and your work in this area, but none of you are working on alignment per se full time or even close to full time AFAIK, and the total effort is clearly far from adequate to the task at hand.
Any other names you can cite?
Thanks, this makes sense to me, and my follow-up is how concerning do you think this situation is?
One perspective I have is that at this point, several years into a potential AI takeoff, with AI companies now worth trillions in aggregate, alignment teams at AI companies still have virtually no professional philosophical oversight (or outside consultants that they rely on), and are kind of winging it based on their own philosophical beliefs/knowledge. It seems rather like trying to build a particle collider or fusion reaction with no physicists on the staff, only engineers.
(Or worse, unlike engineers' physics knowledge, I doubt that receiving a systematic education in fields like ethics and metaethics is a hard requirement for working as an alignment researcher. And even worse, unlike the situation in physics, we don't even have settled ethics/metaethics/metaphilosophy/etc. that alignment researchers can just learn and apply.)
Maybe the AI companies are reluctant to get professional philosophers involved, because in the fields that do have "professional philosophical oversight", e.g., bioethics, things haven't worked out that well. (E.g. human challenge trials being banned during COVID.) But to me, this would be a signal to yell loudly that our civilization is far from ready to attempt or undergo an AI transition, rather than a license to wing it based on one's own philosophical beliefs/knowledge.
As an outsider, the situation seems cray alarming to me, and I'm confused that nobody else is talking about it, including philosophers like you who are in the same overall space and looking at roughly the same things. I wonder if you have a perspective that makes the situation not quite as alarming as it appears to me.
I'm a philosopher who's switched to working on AI safety full-time. I also know there are at least a few philosophers at Anthropic working on alignment.
With regards to your Problems in AI Alignment that philosophers could potentially contribute to:
When I decided to start working on AI, I seriously considered working on the kinds of questions you list. But due to the points above, I chose to do my current work instead.
This reads to me like you're saying "these problems are hard [so Wei Dai is over-rating the importance of working on them]", whereas the inference I would make is "these problems are hard, so we need to slow down AI development, otherwise we won't be able to solve them in time."
I didn't meant to imply that Wei Dai was overrating the problems' importance. I agree they're very important! I was making the case that they're also very intractable.
If I thought solving these problems pre-TAI would be a big increase to the EV of the future, I'd take their difficulty to be a(nother) reason to slow down AI development. But I think I'm more optimistic than you and Wei Dai about waiting until we have smart AIs to help us on these problems.
Do you want to talk about why you're relatively optimistic? I've tried to explain my own concerns/pessimism at https://www.lesswrong.com/posts/EByDsY9S3EDhhfFzC/some-thoughts-on-metaphilosophy and https://forum.effectivealtruism.org/posts/axSfJXriBWEixsHGR/ai-doing-philosophy-ai-generating-hands.
I said a little in another thread. If we get aligned AI, I think it'll likely be a corrigible assistant that doesn't have its own philosophical views that it wants to act on. And then we can use these assistants to help us solve philosophical problems. I'm imagining in particular that these AIs could be very good at mapping logical space, tracing all the implications of various views, etc. So you could ask a question and receive a response like: 'Here are the different views on this question. Here's why they're mutually exclusive and jointly exhaustive. Here are all the most serious objections to each view. Here are all the responses to those objections. Here are all the objections to those responses,' and so on. That would be a huge boost to philosophical progress. Progress has been slow so far because human philosophers take entire lifetimes just to fill in one small part of this enormous map, and because humans make errors so later philosophers can't even trust that small filled-in part, and because verification in philosophy isn't much quicker than generation.
The argument tree (arguments, counterarguments, counter-counterarguments, and so on) is exponentially sized and we don't know how deep or wide we need to expand it, before some problem can be solved. We do know that different humans looking at the same partial tree (i.e., philosophers who have read the same literature on some problem) can have very different judgments as to what the correct conclusion is. There's also a huge amount of intuition/judgment involved in choosing which part of the tree to focus on or expand further. With AIs helping to expand the tree for us, there are potential advantages like you mentioned, but also potential disadvantages, like AIs not having good intuition/judgment about what lines of arguments to pursue, or the argument tree (or AI-generated philosophical literature) becoming too large for any humans to read and think about in a relevant time frame. Many will be very tempted to just let AIs answer the questions / make the final conclusions for us, especially if AIs also accelerate technological progress, creating many urgent philosophical problems related to how to use them safely and beneficially. Or if humans try to make the conclusions, can easily get them wrong despite AI help with expanding the argument tree.
So I think undergoing the AI transition without solving metaphilosophy, or making AIs autonomously competent at philosophy (good at getting correct conclusions by themselves) is enormously risky, even if we have corrigible AIs helping us.
I wrote a post that I think was partly inspired by this discussion. The implication of it here is that I don't necessarily want philosophers to directly try to solve the many hard philosophical problems relevant to AI alignment/safety (especially given how few of them are in this space or concerned about x-safety), but initially just to try to make them "more legible" to others, including AI researchers, key decision makers, and the public. Hopefully you agree that this is a more sensible position.
Yes, I agree this is valuable, though I think it's valuable mainly because it increases the probability that people use future AIs to solve these problems, rather than because it will make people slow down AI development or try very hard to solve them pre-TAI.
I'm not sure but I think maybe I also have a different view than you on what problems are going to be bottlenecks to AI development. e.g. I think there's a big chance that the world would steam ahead even if we don't solve any of the current (non-philosophical) problems in alignment (interpretability, shutdownability, reward hacking, etc.).
I agree that many of the problems on my list are very hard and probably not the highest marginal value work to be doing from an individual perspective. Keep in mind that the list was written 6 years ago, when it was less clear when the AI takeoff would start in earnest, or how many philosophers will become motivated to work on AI safety when AGI became visibly closer. I still had some hope that when the time came, a significant fraction of all philosophers would become self-motivated or would be "called to arms" by a civilization-wide AI safety effort, and would be given sufficient resources including time, so the list was trying to be more comprehensive (listing every philosophical problem that I thought relevant to AI safety) than prioritizing. Unfortunately, the reality is nearly the completely opposite of this.
Currently, one of my main puzzles is why philosophers with public AI x-risk estimates still have numbers in the 10% range, despite reality being near the most pessimistic of my range of expectations, and it looking like that the AI takeoff/transition will occur while most of these philosophical problems will remain in a wide open or totally confused state, and AI researchers seem almost completely oblivious or uncaring about this. Why are they not making the same kind of argument that I've been making, that philosophical difficulty is a reason that AI alignment/x-safety is harder than many think, and an additional reason to pause/stop AI?
I don't think philosophical difficulty is that much of an increase to the difficulty of alignment, mainly because I think that AI developers should (and likely will) aim to make AIs corrigible assistants rather than agents with their own philosophical views that they try to impose on the world. And I think it's fairly likely that we can use these assistants (if we succeed in getting them and aren't disempowered by a misaligned AI instead) to help a lot with these hard philosophical questions.
Any thoughts on Legible vs. Illegible AI Safety Problems, which is in part a response to this?
If this post is indeed cutting-edge and prominent, I would be more surprised by the fact that there are not more 'quant' people reporting on this than by the fact that more philosophers are not working on AI x-risk related issues.
What happens if this is true and AI improvements will primarily be inference driven?
It seems like this would be very bad news for AI companies, because customers would have to pay for accurate AI results directly, on a per-run basis. Furthermore, they would have to pay exponentional costs for a linear increase in accuracy.
As a crude example, would you expect a translation agency to pay four times as much for translations with half as many errors? In either case, you'd still need a human to come along and correct the errors.
Toby wrote this post, which touches on many of the questions you asked. I think it's been significantly under-hyped!
Thanks. I'm also a bit surprised by the lack of reaction to this series given that:
For my part, I simply didn't know the series existed until seeing this post, since this is the only post in the series on EAF. :)
The crux for me is I don't agree that compute scaling has dramatically changed, because I don't think pre-training scaling has gotten much worse returns.
Agreed! The series has been valuable for my personal thinking around this (I quoted the post I linked above as late as yesterday.) Imo, more people should be paying attention to this.
I agree — it seems weird that people haven’t updated very much.
However, I wrote a similarly-purposed (though much less rigorous) post entitled “How To Update if Pre-Training is Dead,” and Vladmir Nesov wrote the following comment (before GPT 5 release), which I would be curious to hear your thoughts on:
Frontier AI training compute is currently increasing about 12x every two years, from about 7e18 FLOP/s in 2022 (24K A100s, 0.3e15 BF16 FLOP/s per chip), to about 1e20 FLOP/s in 2024 (100K H100s, 1e15 BF16 FLOP/s per chip), to 1e21 FLOP/s in 2026 (Crusoe/Oracle/OpenAI Abilene system, 400K chips in GB200/GB300 NVL72 racks, 2.5e15 BF16 FLOP/s per chip). If this trend takes another step, we'll have 1.2e22 FLOP/s in 2028 (though it'll plausibly take a bit longer to get there, maybe 2.5e22 FLOP/s in 2030 instead), with 5 GW training systems.
So the change between GPT-4 and GPT-4.5 is a third of this path. And GPT-4.5 is very impressive compared to the actual original GPT-4 from Mar 2023, it's only by comparing it to more recent models that GPT-4.5 isn't very useful (in its non-reasoning form, and plausibly without much polish). Some of these more recent models were plausibly trained on 2023 compute (maybe 30K H100s, 3e19 FLOP/s, 4x more than the original GPT-4), or were more lightweight models (not compute optimal, and with fewer total params) trained on 2024 compute (about the same as GPT-4.5).
So what we can actually observe from GPT-4.5 is that increasing compute by 3x is not very impressive, but the whole road from 2022 to 2028-2030 is a 1700x-3500x increase in compute from original GPT-4 (or twice that if we are moving from BF16 to FP8), or 120x-250x from GPT-4.5 (if GPT-4.5 is already trained in FP8, which was hinted at in the release video). Judging the effect of 120x from the effect of 3x is not very convincing. And we haven't really seen what GPT-4.5 can do yet, because it's not a reasoning model.
The best large model inference hardware available until very recently (other than TPUs) is B200 NVL8, with 1.5 TB of HBM, which makes it practical to run long reasoning on models with 1-3T FP8 total params that fit in 1-4 nodes (with room for KV caches). But the new GB200 NVL72s that are only starting to get online in significant numbers very recently each have 13.7 TB of HBM, which means you can fit a 7T FP8 total param model in just one rack (scale-up world), and in principle 10-30T FP8 param models in 1-4 racks, an enormous change. The Rubin Ultra NVL576 racks of 2028 will each have 147 TB of HBM, another 10x jump.
If GPT-4.5 was pretrained for 3 months at 40% compute utilization on a 1e20 FLOP/s system of 2024 (100K H100s), it had about 3e26 BF16 FLOPs of pretraining, or alternatively 6e26 FP8 FLOPs. For a model with 1:8 sparsity (active:total params), it's compute optimal to maybe use 120 tokens/param (40 tokens/param from Llama-3-405B, 3x that from 1:8 sparsity). So a 5e26 FLOPs of pretraining will make about 830B active params compute optimal, which means 7T total params. The overhead for running this on B200s is significant, but in FP8 the model fits in a single GB200 NVL72 rack. Possibly the number of total params is even greater, but fitting in one rack for the first model of the GB200 NVL72 era makes sense.
So with GB200 NVL72s, it becomes practical to run (or train with RLVR) a compute optimal 1:8 sparse MoE model pretrained on 2024 compute (100K H100s) with long reasoning traces (in thinking mode). Possibly this is what they are calling "GPT-5".
Going in the opposite direction in raw compute, but with more recent algorithmic improvements, there's DeepSeek-R1-0528 (37B active params, a reasoning model) and Kimi K2 (30B active params, a non-reasoning model), both pretrained for about 3e24 FLOPs and 15T tokens, 100x-200x less than GPT-4.5, but with much more sparsity than GPT-4.5 could plausibly have. This gives the smaller models about 2x more in effective compute, but also they might be 2x overtrained compared to compute optimal (which might be 240 tokens/param, from taking 6x the dense value for 1:32 sparsity), so maybe the advantage of GPT-4.5 comes out to 70x-140x. I think this is a more useful point of comparison than the original GPT-4, as a way of estimating the impact of 5 GW training systems of 2028-2030 compared to 100K H100s of 2024.
I don't know what to make of that. Obviously Vladimir knows a lot about state of the art compute, but there are so many details there without them being drawn together into a coherent point that really disagrees with you or me on this.
It does sound like he is making the argument that GPT 4.5 was actually fine and on trend. I don't really believe this, and don't think OpenAI believed it either (there are various leaks they were disappointed with it, they barely announced it, and then they shelved it almost immediately).
I don't think the argument about original GPT-4 really works. It improved because of post-training, but did they also add that post-training on GPT-4.5? If so, then the 10x compute really does add little. If not, then why not? Why is OpenAI's revealed preference to not put much effort into enhancing their most expensive ever system if not because they didn't think it was that good?
There is a similar story re reasoning models. It is true that in many ways the advanced reasoning versions of GPT-4o (e.g. o3) are superior to GPT-4.5, but why not make it a reasoning model too? If that's because it would use too much compute or be too slow for users due to latency, then these are big flaws with scaling up larger models.
Shouldn't we be able to point to some objective benchmark if GPT-4.5 was really off trend? It got 10x the SWE-Bench score of GPT-4. That seems like solid evidence that additional pretraining continued to produce the same magnitude of improvements as previous scaleups. If there were now even more efficient ways than that to improve capabilities, like RL post-training on smaller o-series models, why would you expect OpenAI not to focus their efforts there instead? RL was producing gains and hadn't been scaled as much as self-supervised pretraining, so it was obvious where to invest marginal dollars. GPT-5 is better and faster than 4.5. This doesn't mean pretraining suddenly stopped working or went off trend from scaling laws though.
It's very difficult to do this with benchmarks, because as the models improve benchmarks come and go. Things that used to be so hard that it couldn't do better than chance quickly become saturated and we look for the next thing, then the one after that, and so on. For me, the fact that GPT-4 -> GPT4.5 seemed to involve climbing about half of one benchmark was slower progress than I expected (and the leaks from OpenAI suggest they had similar views to me). When GPT-3.5 was replaced by GPT-4, people were losing their minds about it — both internally and on launch day. Entirely new benchmarks were needed to deal with what it could do. I didn't see any of that for GPT-4.5.
I agree with you that the evidence is subjective and disputable. But I don't think it is a case where the burden of proof is disproportionately on those saying it was a smaller jump than previously.
(Also, note that this doesn't have much to do with the actual scaling laws, which are a measure of how much prediction error of the next token goes down when you 10x the training compute. I don't have reason to think that has gone off trend. But I'm saying that the real-world gains from this (or the intuitive measure of intelligence) has diminished, compared to the previous few 10x jumps. This is definitely compatible. e.g. if the model only trained on wikipedia plus an unending supply of nursery rhymes, its prediction error would continue to drop as more training happened, but its real world capabilities wouldn't improve by continued 10x jumps in the number of nursery rhymes added in. I think the real world is like this where GPT-4-level systems are already trained on most books ever written and much of the recorded knowledge of the last 10,000 years of civilisation, and it makes sense that adding more Reddit comments wouldn't move the needle much.)
Yes, what you are scaling matters just as much as the fact that you are scaling. So now developers are scaling RL post training and pretraining using higher quality synthetic data pipelines. If the point is just that training on average internet text provides diminishing real world returns in many real-world use cases, then that seems defensible; that certainly doesn't seem to be the main recipe any company is using for pushing the frontier right now. But it seems like people often mistake this for something stronger like "all training is now facing insurmountable barriers to continued real world gains" or "scaling laws are slowing down across the board" or "it didn't produce significant gains on meaningful tasks so scaling is done." I mentioned SWE-Bench because that seems to suggest significant real world utility improvements rather than trivial prediction loss decrease. I also don't think it's clear that there is such an absolute separation here - to model the data you have to model the world in some sense. If you continue feeding multimodal LLM agents the right data in the right way, they continue improving on real world tasks.
I'll just add a comment that Ord did an 80k podcast on this topic here.
This is a really compelling post. This seems like the sort of post that could have a meaningful impact on the opinions of people in the finance/investment world who are thinking about AI. I would be curious to see how equity research analysts and so on would react to this post.
This is a very strong conclusion and seems very consequential if true:
I was curious to see if you had a similar analysis that supports the assertion that "the scaling up of pre-training compute also stalled". Let me know if I missed something important. For the convenience of other readers, here are some pertinent quotes from your previous posts.
From "Inference Scaling Reshapes AI Governance" (February 12, 2025):
From "The Extreme Inefficiency of RL for Frontier Models" (September 19, 2025):
I broadly don't think inference scaling is the only path, primarily because I disagree with the claim that pre-training returns declined much, and attribute the GPT-4.5 evidence as mostly a case of broken compute promises making everything disappointing.
I also have a hypothesis that current RL is mostly serving as an elicitation method for pre-trained AIs.
We shall see in 2026-2027 whether this remains true.
Could you elaborate or link to somewhere where someone makes this argument? I'm curious to see if a strong defense can be made of self-supervised pre-training of LLMs continuing to scale and deliver worthwhile, significant benefits.
I currently can't find a source, but to elaborate a little bit, my reason for thinking this is that the GPT-4 to GPT-4.5 scaleup used 15x the compute instead of 100x the compute, and I remember that 10x compute is enough to be competitive with the current algorithmic improvements that don't involve scaling up models, whereas 100x compute increases result in the wow moments we associated with GPT-3 to GPT-4, and the GPT-5 release was not a scale up of compute, but instead productionizing GPT-4.5.
I'm more in the camp of "I find little reason to believe that pre-training returns have declined" here.
I’ll just mention that, for what it’s worth, the AI researcher and former OpenAI Chief Scientist Ilya Sutskever thinks the scaling of pre-training for LLMs has run out of steam. Dario Amodei, the CEO of Anthropic, has also said things that seem to indicate the scaling of pre-training no longer has the importance it once did.
Other evidence would be reporters talking to anonymous engineers inside OpenAI and Meta who have expressed disappointment with the results of scaling pre-training. Toby mentioned this in another blog post and I quoted the relevant paragraph in a comment here.
Isn't the point just that the amount of compute used for RL training is now roughly the same as the amount of compute used for self-supervised pre-training? Because if this is true, then obviously scaling up RL training compute another 1,000,000x is obviously not feasible.
My main takeaway from this post is not whether RL training would continue to provide benefits if it were scaled up another 1,000,000x, just that the world doesn't have nearly enough GPUs, electricity, or investment capital for that to be possible.
Maybe or maybe not - people also thought we would run out of training data years ago. But that has been pushed back and maybe won't really matter given improvements in synthetic data, multimodal learning, and algorithmic efficiency.
What part do you think is uncertain? Do you think RL training could become orders of magnitude more compute efficient?
Thank you, Toby et al., for this characteristically clear and compelling analysis and discussion. The argument that RL scaling is breathtakingly inefficient and may be hitting a hard limit is a crucial consideration for timelines.
This post made me think about the nature of this bottleneck, and I'm curious to get the forum's thoughts on a high-level analogy. I'm not an ML researcher, so I’m offering this with low confidence, but it seems to me there are at least two different "types" of hard problems.
1. A Science Bottleneck (Fusion Power): Here, the barrier appears to be fundamental physics. We need to contain a plasma that is inherently unstable at temperatures hotter than the sun. Despite decades of massive investment and brilliant minds, we can't easily change the underlying laws of physics that make this so difficult. Progress is slow, and incentives alone can't force a breakthrough.
2. An Engineering Bottleneck (Manhattan Project): Here, the core scientific principle was known (nuclear fission). The barrier was a set of unprecedented engineering challenges: how to enrich enough uranium, how to build a stable reactor, etc. The solution, driven by immense incentives, was a brute-force, parallel search for any viable engineering path (e.g., pursuing gaseous diffusion, electromagnetic separation, and plutonium production all at once).
This brings me back to the RL scaling issue. I'm wondering which category this bottleneck falls into.
From the outside, it feels more like an engineering or "Manhattan Project" problem. The core scientific discovery (the Transformer architecture, the general scaling paradigm) seems to be in place. The bottleneck Ord identifies is that one specific method (RL - likely PPO based) is significantly compute-inefficient and hard to continue scaling.
But the massive commercial incentives at frontier labs aren't just to make this one inefficient method 1,000 or 1,000,000x bigger. The incentive is to invent new, more efficient methods to achieve the same goal or similar.
We've already seen a small-scale example of this with the rapid shift from complex RLHF to the more efficient Direct Preference Optimization (DPO). This suggests the problem may not be a fundamental "we can't continue to improve models" barrier, but an engineering one: "this way of improving models is too expensive and unstable."
If this analogy holds, it seems plausible that the proprietary work at the frontier isn't just grinding on the inefficient RL problem, but is in a "Manhattan"-style race to find a new algorithm or architecture that bypasses this specific bottleneck.
This perspective makes me less confident that this particular bottleneck will be the one that indefinitely pushes out timelines, as it seems like exactly the kind of challenge that massive, concentrated incentives are historically good at solving.
I could be completely mischaracterizing the nature of the challenge, though, and still feel quite uncertain. I'd be very interested to hear from those with more technical expertise if this framing seems at all relevant or if the RL bottleneck is, in fact, closer to a fundamental science or "Fusion" problem.
I understand where you are coming from, and you are certainly not alone in trying to think about AI progress in terms of analogies like this. But I want to explain why I don't think such discussions — which are common — will take us down a productive route.
I don't think anyone can predict the future based on this kind of reasoning. We can guess and speculate, but that's it. It's always possible, in principle, that, at any time, new knowledge could be discovered that would have a profound impact on technology. How likely is that in any particular case? Very hard to say. Nobody really knows.
There are many sorts of technologies that at least some experts think should, in principle, be possible and for which, at least in theory, there is a very large incentive to create, yet still haven't been created. Fusion is a great example, but I don't think we can draw a clean distinction between "science" on the one hand and "engineering" on the other and say science is much harder and engineering is much easier, such that if we want to find out how hard it will be to make fundamental improvements in reinforcement learning, we just have to figure out whether it's a "science" problem or an "engineering" problem. There's a vast variety of science problems and engineering problems. Some science problems are much easier than some engineering problems. For example, discovering a new exoplanet and figuring out its properties, a science problem, is much easier than building a human settlement on Mars, an engineering problem.
What I want to push back against in EA discourse and AGI discourse more generally is unrigorous thinking. In the harsh but funny words of the physicist David Deutsch (emphasis added):
If LLMs' progress on certain tasks has improved over the last 7 years for certain specific reasons, and now we have good reasons to think those reasons for improvement won't be there much longer going forward, then of course you can say, "Well, maybe someone will come up with some other way to keep progress going!" Maybe they will, maybe they won't, who knows? We've transitioned from a rigorous argument based on evidence about LLM performance (mainly performance on benchmarks) and a causal theory of what accounts for that progress (mainly scaling of data and compute) to a hand-wavey idea about how maybe somebody will figure it out. Scaling you can track on a chart, but somebody figuring out a new idea like that is not something you can rigorously say will take 2 years or 20 years or 200 years.
The unrigorous move is:
There is a statistical trend that is caused by certain factors. At some point fairly soon, those factors will not be able to continue causing the statistical trend. But I want to keep extrapolating the statistical trend, so I'm going to speculate that new causal factors will appear that will keep the trend going.
That doesn't make any sense!
To be fair, people do try to reach for explanations of why new causal factors will appear, usually appealing to increasing inputs to AI innovation, such as the number of AI researchers, the number of papers published, improvements in computer hardware, and the amount of financial investment. But we currently have no way of predicting how exactly the inputs to science, technology, or engineering will translate into the generation of new ideas that keep progress going. We can say more is better, but we can't say X amount of dollars, Y amount of researchers, and Z amount of papers is enough to continue recent LLM progress. So, this is not a rigorous theory or model or explanation, but just a hand-wavey guess about what might happen. And to be clear, it might happen, but it might not, and we simply don't know! (And I don't think there's any rigour or much value in the technique of trying to squeeze Bayesian blood from a stone of uncertainty by asking people to guess numbers of how probable they think something is.)
So, it could take 2 years and it could take 20 years (or 200 years), and we don't know, and we probably can't find out any other way than just waiting and seeing. But how should we act, given that uncertainty?
Well, how would we have acted if LLMs had made no progress over the last 7 years? The same argument would have applied: anyone at any time could come up with the right ideas to make AI progress go forward. Making reinforcement learning orders of magnitude more efficient is something someone could have done 7 years ago. It more or less has nothing to do with LLMs. Absent the progress in LLMs would we have thought: "oh, surely, somebody's going to come up with a way to make RL vastly more efficient sometime soon"? Probably not, so we probably shouldn't think that now. If the reason for thinking that is just wanting to keep extrapolating the statistical trend, that's not a good reason.
There is more investment in AI now in the capital markets, but, as I said above, that doesn't allow us to predict anything specific. Moreover, it seems like very little of the investment is going to fundamental AI research. It seems like almost all the money is going toward expenses much more directly relating to productizing LLMs, such as incremental R&D, the compute cost of training runs, and building datacentres (plus all the other expenses related to running a large tech company).
YB, thank you for the pushback. You’ve absolutely convinced me that my “science vs. engineering” analogy was unrigorous, and your core point about extrapolating a trend by assuming a new causal factor will appear is the correct null hypothesis to hold.
What I’m still trying to reconcile, specifically regarding RL efficiency improvements, is a tension between what we can observe and what may be hidden from view.
I expect Toby’s calculations are 100% correct. Your case is also rigorous and evidence-based: RL has been studied for decades, PPO (2017) was incremental, and we shouldn’t assume 10x-100x efficiency gains without evidence. The burden of proof is on those claiming breakthroughs are coming.
But RL research seems particularly subject to information asymmetry:
• Labs have strong incentives to keep RL improvements proprietary (competitive advantage in RLHF, o1-style reasoning, agent training)
• Negative results rarely get published (we don’t know what hasn’t worked)
• The gap between “internal experiments” and “public disclosure” may be especially long for RL
We’ve seen this pattern before - AlphaGo’s multi-year information lag, GPT-4’s ~7-month gap. But for RL specifically, the opacity seems greater. OpenAI uses RL for o1, but we don’t know their techniques, efficiency gains, or scaling properties. DeepMind’s work on RL is similarly opaque.
This leaves me uncertain about future RL scaling specifically. On one hand, you’re right that decades of research suggest efficiency improvements are hard. On the other hand, recent factors (LLMs as reward models, verifiable domains for self-play, unprecedented compute for experiments) combined with information asymmetry make me wonder if we’re reasoning from incomplete data.
The specific question: Does the combination of (a) new factors like LLMs/verifiable domains, plus (b) the opacity and volume of RL research at frontier labs, warrant updating our priors on RL efficiency? Or is this still the same “hand-waving” trap - just assuming hidden progress exists because we expect the trend to continue?
On the action-relevant side: if RL efficiency improvements would enable significantly more capable agents or self-improvement, should safety researchers prepare for that scenario despite epistemic uncertainty? The lead times for safety work seem long enough that “wait and see” may not be viable.
For falsifiability: we should know within 18-24 months. If RL-based systems (agents, reasoners) don’t show substantial capability gains despite continued investment, that would validate skepticism. If they do, it would suggest there were efficiency improvements we couldn’t see from outside.
I’m genuinely uncertain here and would value a better sense of whether the information asymmetry around RL research specifically changes how we should weigh the available evidence?
I guess there could have recently been a major breakthrough in RL at any of the major AI companies that the public doesn’t know about yet. Or there could be one soon that we wouldn’t know about right away. But why think that is the case? And why think that is more like at this particular point in time than any other time within the last 10 years or so?
Can you explain what "LLMs as reward models" and "verifiable domains for self-play" mean and why these would make RL dramatically more compute efficient? I’m guessing that "LLMs as reward models" means that the representational power of LLMs is far greater than for RL agents in the past. But hasn’t RLHF been used on LLMs since before the first version of ChatGPT? So wouldn’t our idea of how quickly LLMs learn or improve using RL from the past 3 years or so already account for LLMs as world models?
By "verifiable domains for self-play", do you we have benchmarks or environments that automatically gradable and can provide a reward signal without a human manually taking any action? If so, again, that seems like something that should already be accounted for in the last 3 years or so of data.
If what you’re saying is that LLMs as reward models or verifiable domains for self-play could contribute to research or innovation in RL such that a major breakthrough in RL compute efficiency is more likely, I don’t follow the reasoning there.
You also mentioned "unprecedented compute for experiments", which maybe could be a factor that will contribute to the likelihood of such a breakthrough, but who knows. Why couldn’t you test an idea for more compute efficient RL on a small number of GPUs first and see if you get early results? Why would having a lot more GPUs help? With a lot of GPUs, you could test more ideas in parallel, but is the limiting factor really the ability to test ideas or is it coming up with new ideas in the first place?
Yarrow, these are fantastic, sharp questions. Your “already accounted for” point is the strongest counter-argument I’ve encountered.
You’re correct in your interpretation of the terms. And your core challenge—if LLM reward models and verifiable domains have existed for ~3 years, shouldn’t their impact already be visible?—is exactly what I’m grappling with.
Let me try to articulate my hypothesis more precisely:
The Phase 1 vs Phase 2 distinction:
I wonder if we’re potentially conflating two different uses of RL that might have very different efficiency profiles:
1. Phase 1 (Alignment/Style): This is the RLHF that created ChatGPT—steering a pretrained model to be helpful/harmless. This has been done for ~3 years and is probably what’s reflected in public benchmark data.
2. Phase 2 (Capability Gains): This is using RL to make models fundamentally more capable at tasks through extended reasoning or self-play (e.g., o1, AlphaGo-style approaches).
My uncertainty is: could “Phase 2” RL have very different efficiency characteristics than “Phase 1”?
Recent academic evidence:
Some very recent papers seem to directly address this question:
• A paper by Khatri et al., "The Art of Scaling Reinforcement Learning Compute for LLMs" (arXiv: 2510.13786), appears to show that simple RL methods do hit hard performance ceilings (validating your skepticism), but that scaling RL is a complex “art.” It suggests a specific recipe (ScaleRL) can achieve predictable scaling. This hints the bottleneck might be “know-how” rather than a fundamental limit.
• Another paper by Tan et al., "Scaling Behaviors of LLM Reinforcement Learning Post-Training: An Empirical Study in Mathematical Reasoning" (arXiv: 2509.25300), on scaling RL for math found that performance is more bound by data quality (like from verifiable domains) than just compute, and that larger models are more compute- and sample-efficient at these tasks.
Why this seems relevant:
This research suggests “Phase 1” RL (simple, public methods) and “Phase 2” RL (complex recipes, high-quality data, large models) might have quite different scaling properties.
This makes me wonder if the scaling properties from prior RL research might not fully capture what’s possible in this new regime: very large models + high-quality verifiable domains + substantial compute + the right training recipe. Prior research isn’t irrelevant, but perhaps extrapolation from it is unreliable when the conditions are changing this much?
If labs have found (or are close to finding) these “secret recipes” for scalable RL, that could explain continued capital investment from well-informed actors despite public data showing plateaus.
The action-relevant dilemma:
Even granting the epistemic uncertainty, there seems to be a strategic question: Given long lead times for safety research, should researchers hedge by preparing for RL efficiency improvements, even if we can’t confidently predict them?
The asymmetry: if we wait for public evidence before starting safety work, and RL does become substantially more efficient (because a lab finds the right “recipe”), we’ll have even less lead time. But if we prepare unnecessarily, we’ve misallocated resources.
I don’t have a clean answer to what probability threshold for a potential breakthrough justifies heightened precautionary work. But the epistemic uncertainty itself—combined with some papers suggesting the scaling regime might be fundamentally different than assumed—makes me worry whether we’re evaluating the efficiency of propellers while jet engines are being invented in private.
Does this change your analysis at all, or do you think the burden of proof still requires more than theoretical papers about potential scaling regimes?
Thank you for your kindness. I appreciate it. :)
Do the two papers you mentioned give specific quantitative information about how much LLM performance increases as the compute used for RL scales? And is it a substantially more efficient scaling than what Toby Ord assumes in the post above?
In terms of AI safety research, this is getting into a very broad, abstract, general, philosophical point, but, personally, I'm fairly skeptical of the idea that anybody today will be able to do AI safety research now that can be applied to much more powerful, much more general AI systems in the future. I guess if you think the more powerful, more general AI systems of the future will just be bigger versions of the type of systems we have today, then it makes sense why you'd think AI safety research would be useful now. But I think there are good reasons for doubting that, and LLM scaling running out of steam is just one of those good reasons.
To take a historical example, the Machine Intelligence Research Institute (MIRI) had some very specific ideas about AI safety and alignment dating back to before the deep learning revolution that started around 2012. I
recall having an exchange with Eliezer Yudkowsky, who co-founded MIRI and does research there, on Facebook sometime around 2015-2017 where he expressed doubt that deep learning was the way to get to AGI and said his best bet was thatsymbolic AIwas the most promising approach. At some point, he must have changed his mind, but I can't find any writing he's done or any talk or interview where he explains when and why his thinking changed.[Edited on 2026-01-18 at 20:55 UTC to add: I misremembered some important details about my exchanges on Facebook with Eliezer Yudkowsky and another person at MIRI, Rob Bensinger, about deep learning and other AI paradigms around 2016-2018. Take my struckthrough recollections above as unreliable memory. I went through the trouble of digging up some old Facebook comments and detailed what I found here.]
In any case, one criticism — which I agree with — that has been made of Yudkowsky's and MIRI's current ideas about AI safety and alignment is that these ideas have not been updated in the last 13 years, and remain the same ideas that Yudkowsky and MIRI were advocating before the deep learning revolution. And there are strong reasons to doubt they still apply to frontier AI systems, if they ever did. What we would expect from Yudkowsky and MIRI at this point is either an updating of their ideas about safety and alignment, or an explanation of why their ideas developed with symbolic AI in mind should still apply, without modification, to deep learning-based systems. It's hard to understand why this point hasn't been addressed, particularly since people have been bringing it up for years. It comes across, in the words of one critic, as a sign of thinkers who are "persistently unable to update their priors."
What I just said about MIRI's views on AI safety and alignment could be applied to AI safety more generally. Ideas developed on the assumption that current techniques, architectures, designs, or paradigms will scale all the way to AGI could turn out to be completely useless and irrelevant if it turns out that more powerful and more general AI systems will be built using entirely novel ideas that we can't anticipate yet. You used an aviation analogy. Let me try my own. Research on AI safety that assumes LLMs will scale to AGI and is therefore based on studying the properties peculiar to LLMs might turn out to be a waste of time if technology goes in another direction, just as aviation safety research that assumed airships would be the technology that will underlie air travel and focused on the properties of hydrogen and helium gas has no relevance to a world where air travel is powered by airplanes that are heavier than air.
It's relevant to bring up at this point that a survey of AI experts found that 76% of them think that it's unlikely or very unlikely that current AI techniques, such as LLMs, will scale to AGI. There are many reasons to agree with the majority of experts on this question, some of which I briefly listed in a post here.
Because I don't see scaling up LLMs as a viable path to AGI, I personally don't see much value in AI safety research that assumes that it is a viable path. (To be clear, AI safety research that is about things like how LLM-based chatbots can safely respond to users who express suicidal ideation, and not be prompted into saying something harmful or dangerous, could potentially be very valuable, but that's about present-day use cases of LLMs and not about AGI or global catastrophic risk, which is what we've been talking about.) In general, I'm very sympathetic to a precautionary, "better safe than sorry" approach, but, to me, AI safety or alignment research can't even be justified on those grounds. The chance of LLMs scaling up to AGI seems so remote.
It's also unlike the remote chance of an asteroid strike, where we have hard science that can be used to calculate that probability rigorously. It's more like the remote chance that the Large Hadron Collider (LHC) would create a black hole, which can only be assigned a probability above zero because of fundamental epistemic uncertainty, i.e., based on the chance that we've gotten the laws of physics wrong. I don't know if I can quite put my finger on why I don't like a form of argument in favour of practical measures to mitigate existential risk based on fundamental epistemic uncertainty. I can point out that it would seem to lead to have some very bizarre implications.
For example, what probability do we assign to the possibility that Christian fundamentalism is correct? If we assign a probability above zero, then this leads us literally to Pascal's wager, because the utility of heaven is infinite, the disutility of hell is infinite, and the cost of complying with the Christian fundamentalist requirements for going to heaven are not only finite but relatively modest. Reductio ad absurdum?
By contrast, we know for sure dangerous asteroids are out there, we know they've hit Earth before, and we have rigorous techniques for observing them, tracking them, and predicting their trajectories. When NASA says there's a 1 in 10,000 chance of an asteroid hitting Earth, that's an entirely different kind of a probability than if a Bayesian-utilitarian guesses there's a 1 in 10,000 chance that Christian fundamentalism is correct, that the LHC will create a black hole, or that LLMs will scale to AGI within two decades.
One way I can try to articulate my dissatisfaction with the argument that we should do AI safety research anyway, just in case, is to point out there's no self-evident or completely neutral or agnostic perspective from which to work on AGI safety. For example, what if the first AGIs we build would otherwise have been safe, aligned, and friendly, but by applying our alignment techniques developed from AI safety research, we actually make them incredibly dangerous and cause a global catastrophe? How do we know which kind of action is actually precautionary?
I could also make the point that, in some very real and practical sense, all AI research is a tradeoff between other kinds of AI research that could have been done instead. So, maybe instead of focusing on LLMs, it's wiser to focus on alternative ideas like energy-based models, program synthesis, neuromorphic AI, or fundamental RL research. I think the approach of trying to squeeze Bayesian blood from a stone of uncertainty by making subjective guesses of probabilities can only take you so far, and pretty quickly the limitations become apparent.
To fully make myself clear and put my cards completely on the table, I don't find effective altruism's treatment of the topic of near-term AGI to be particularly intellectually rigorous or persuasive, and I suspect at least some people in EA who currently think very near-term AGI is very likely will experience a wave of doubt when the AI investment bubble pops sometime within the next few years. There is no external event, no evidence, and no argument that can compel someone to update their views if they're inclined enough to resist updating, but I suspect there are some people in EA who will interpret the AI bubble popping as new information and will take it as an opportunity to think carefully about their views on near-term AGI.
But if you think that very near-term AGI is very likely, and if you think LLMs very likely will scale to AGI, then this implies an entirely different idea about what should be done, practically, in the area of AI safety research today, and if you're sticking to those assumptions, then I'm the wrong person to ask about what should be done.
Yarrow, thank you for this sharp and clarifying discussion.
You have completely convinced me that my earlier arguments from "investment as a signal" or "LHC/Pascal's Wager" were unrigorous, and I concede those points.
I think I can now articulate my one, non-speculative crux.
The "so what" of Toby Ord's (excellent) analysis is that it provides a perfect, rigorous, "hindsight" view of the last paradigm—what I've been calling "Phase 1" RL for alignment.
My core uncertainty isn't speculative "what-if" hope. It's that the empirical ground is shifting.
The very recent papers we discussed (Khatri et al. on the "art" of scaling, and Tan et al. on math reasoning) are, for me, the first public, rigorous evidence for a "Phase 2" capability paradigm.
• They provide a causal mechanism for why the old, simple scaling data may be an unreliable predictor.
• They show this "Phase 2" regime is different: it's not a simple power law but a complex, recipe-dependent "know-how" problem (Khatri), and it has different efficiency dynamics (Tan).
This, for me, is the action-relevant dilemma.
We are no longer in a state of "pure speculation". We are in a state of grounded, empirical uncertainty where the public research is just now documenting a new, more complex scaling regime that the private labs have been pursuing in secret.
Given that the lead time for any serious safety work is measured in years, and the nature of the breakthrough is a proprietary, secret "recipe," the "wait for public proof" strategy seems non-robust.
That's the core of my concern. I'm now much clearer on the crux of the argument, and I can't thank you enough for pushing me to be more rigorous. This has been incredibly helpful, and I'll leave it there.
Hello, Matt. Let me just say I really appreciate your friendly, supportive, and positive approach to this conversation. It's very nice. Discussions on the EA Forum can get pretty sour sometimes, and I'm probably not entirely blameless in that myself.
You don't have to reply if you don't want, but I just wanted to follow up in case you still did.
Can you explain what you mean about the data efficiency of the new RL techniques in the papers you mentioned? You say it's more complex, but that doesn't help me understand.
By the way, did you use an LLM like Claude or ChatGPT to help write your comment? It has some of the hallmarks of LLM writing for me. I'm just saying this to help you — you may not realize how much LLMs' writing style sticks out like a sore thumb (depending on how you use them) and it will likely discourage people from engaging with you if they detect that. I keep encouraging people to trust themselves as writers, trust their own voice, and reassuring them that the imperfections of their writing doesn't make us, the readers, like it less, it makes us like it more.