This report was mostly written by Claude Opus 4.6. We manually checked all claims and didn’t find any errors.
Summary
- We summarise the results of a survey carried out before the 2026 Summit on Existential Security. Respondents were Summit attendees: leaders and key thinkers in the x-risk and AI safety communities.
- The survey asked attendees about their estimates of existential risk, AGI timelines, and resource allocation priorities.
Survey data comes from the 59 respondents who consented to their answers being shared publicly.[1] Data was collected in February 2026.
X-risk and timelines
| Key results | |
| Probability of human extinction or permanent human disempowerment before 2100 | Median: 25% Mean: 34% |
| 50% chance of AGI | Median: 2033 Mean: 2034 |
| 25% chance of AGI (n=48) | Median: 2030 Mean: 2030 |
| Assigned ≥50% chance of AGI by 2030 | 22% of respondents |
| Assigned ≥50% chance of AGI by 2035 | 73% of respondents |
We defined AGI as:
An AI system (or collection of systems) that can fully automate the vast majority (>90%) of roles in the 2025 economy. A job is fully automatable when machines could be built to carry out the job better and more cheaply than human workers. Think feasibility, not adoption.
Resource allocation
- The strongest consensus in resource allocation is that the x-risk community should direct more effort towards AI-enabled human takeover scenarios (mean score +0.78 on a −2 to +2 scale, with 43 of 59 saying ‘More’ or ‘Much more’) and towards better futures work (mean +0.51).
- Respondents lean slightly towards fewer resources on misaligned AI takeover (mean −0.14), though this finding is driven almost entirely by those with longer AGI timelines.
- The sub-fields that respondents think deserve significant additional investment are advocacy, policy and governance, and corporate advocacy.
Areas of debate and consensus at the event
- Summit attendees broadly agree that talent is the binding constraint on AI safety, and that risks from aligned AI (such as authoritarian lock-in) deserve far more attention than they currently receive.
- Key debates remain over how well alignment is actually going and whether automated alignment research is a genuine strategy or merely a hope.
Existential risk estimates
Respondents were asked:
“What is the probability of human extinction or permanent human disempowerment before 2100?”
Summary statistics
| Mean | Median | Std Dev | IQR | Range |
|---|---|---|---|---|
| 34.1% | 25.0% | 24.2% | 14–50% | 5–95% |
Distribution
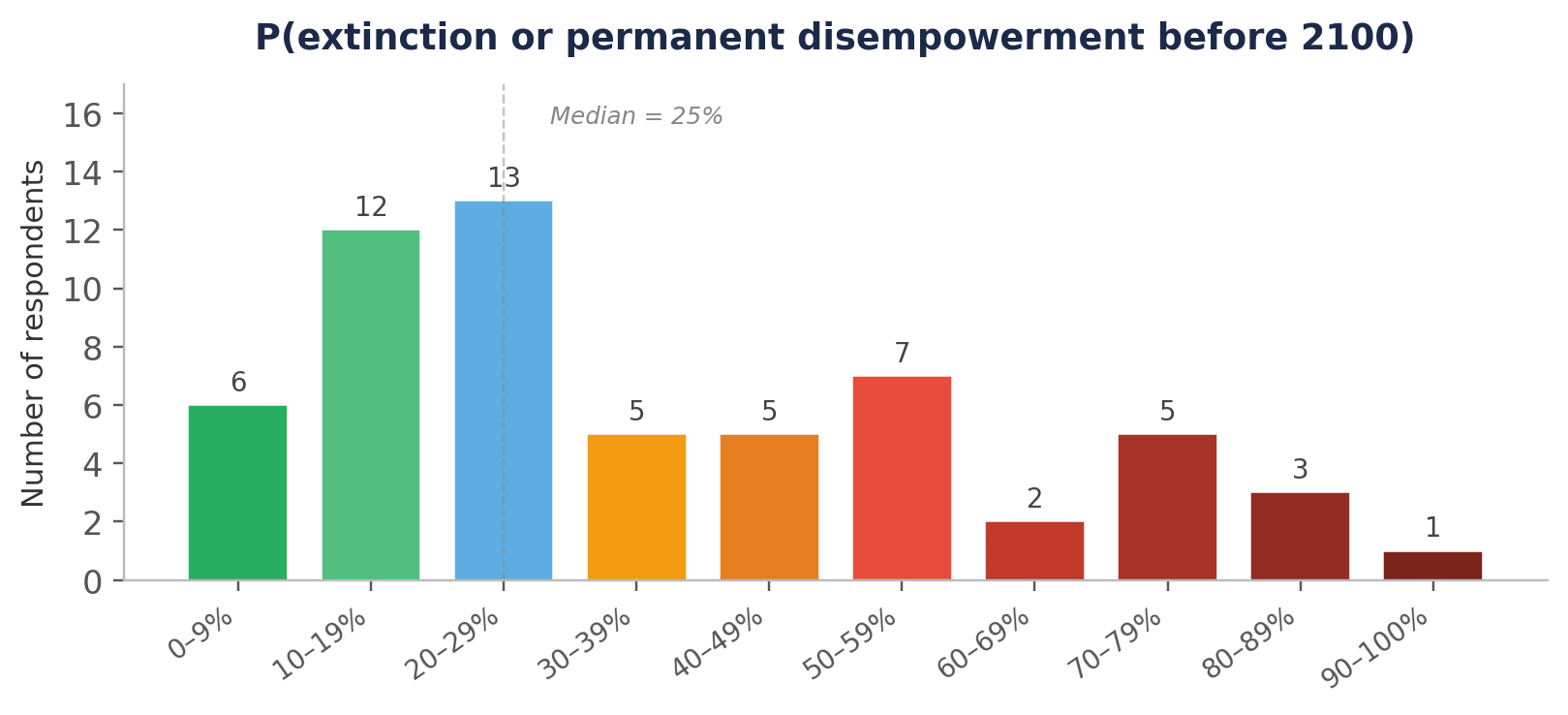
The distribution is right-skewed with a long tail of high estimates. The modal range is 20–29%, but there is a secondary cluster at 50%+, with 9 respondents (15%) placing their estimate at 70% or above. Several respondents offered important caveats: some distinguished between extinction and disempowerment, noting that permanent disempowerment is not necessarily an existential catastrophe if human values are preserved.
A note on interpretation: these figures reflect the views of a self-selected group of practitioners working on existential risk. The sample therefore likely skews towards people who have already concluded that these risks warrant dedicated attention.
Notable comments
“I’m not counting it to be human disempowerment if reflected human preferences maintain a major influence on the future, even if humans as they exist today aren’t around.”
“I’d put the chance of human extinction itself below 10%, but I think there’s a significant chance of permanent human disempowerment (which may not in itself mean that the future will be bad/devoid of value).”
“I’m reading human disempowerment as a future where humanity has lost control and few to none of our values are preserved. This would be distinct from a future where we deliberately empower a successor species that retains many of our values, even if AIs and not humans are the ones calling the shots.”
“Competition between companies and countries means we build superintelligence. And I just don’t see how humans retain control of something way more capable and intelligent than us.”
“I think full extinction is fairly hard and most of my probability comes from effects downstream of technological advancement (i.e. nuclear war from civilisational collapse). ‘Permanent human disempowerment’ is hard to define — to what extent are most of us in control of what we spend our time doing even today?”
“If you see progress as fundamentally disempowering, I think extinction is also quite likely. Because ceding control, with whatever alignment methods, will likely not go well. I think we can avoid disempowerment.”
AGI timelines
Respondents were asked:
“In what year do you estimate there's a 50% chance we will have developed AGI?”.
An optional question asked the same at 25% probability. Our definition of AGI was:
“An AI system (or collection of systems) that can fully automate the vast majority (>90%) of roles in the 2025 economy. A job is fully automatable when machines could be built to carry out the job better and more cheaply than human workers. Think feasibility, not adoption.”
Summary statistics
| 50% AGI (n=59) | 25% AGI (n=48) | |
|---|---|---|
| Mean | 2034.3 | 2030.0 |
| Median | 2033 | 2030 |
| IQR | 2031–2036 | — |
| Range | 2027–2045 | 2026–2040 |
Distribution of AGI estimates
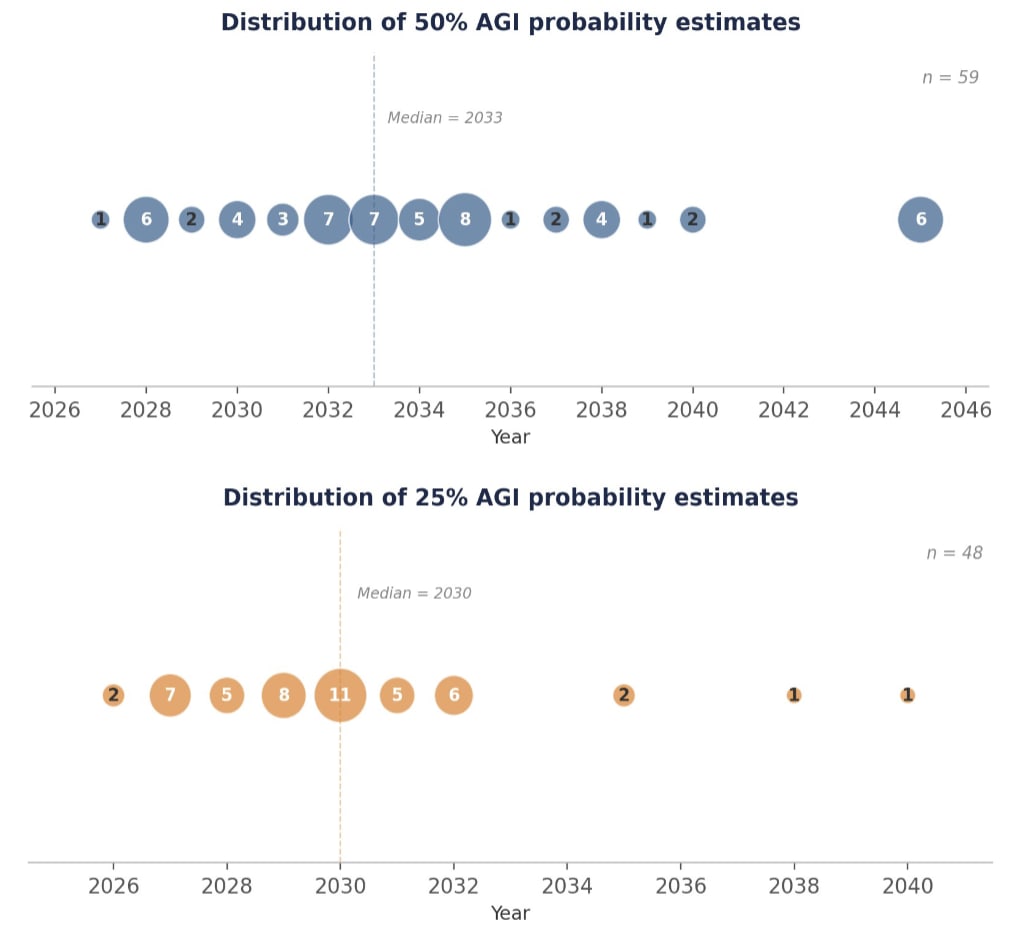
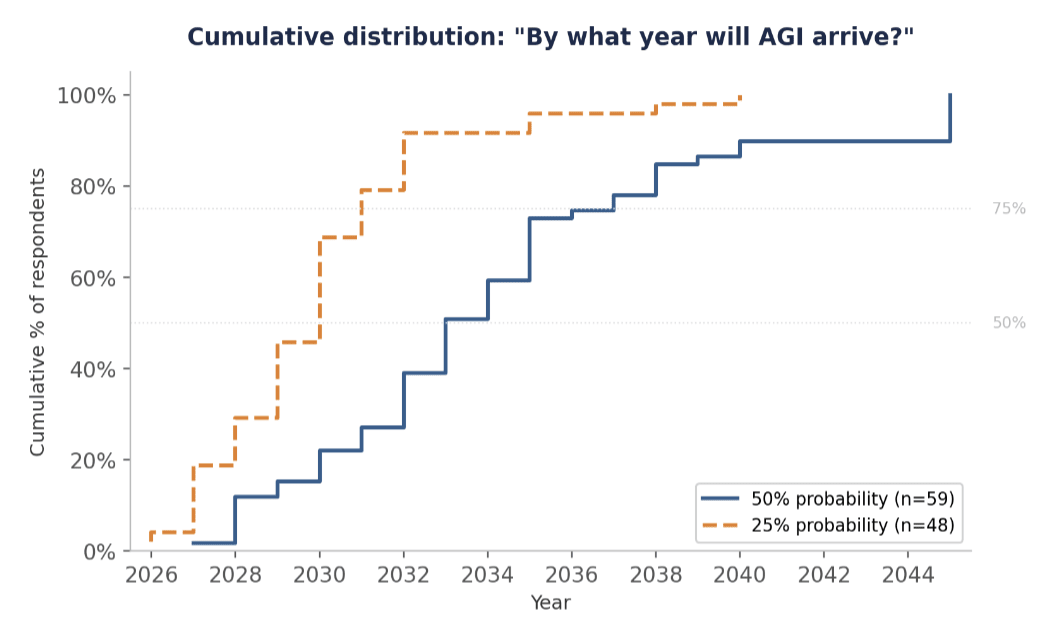
The bulk of 50% AGI estimates cluster in the 2030–2035 range, with 73% of respondents placing their 50% estimate before the end of 2035. The 25% estimates are more tightly concentrated, with an IQR of just 2028–2031, though a handful of outliers extend as far as 2040. Several respondents noted that the definition’s inclusion of physical labour roles pushed their estimates later than they would be for cognitive-only AGI.
Notable comments
“I think >10% of roles in the 2025 economy are either manual or otherwise require human-like bodies: construction, barbers, restaurant server, etc. If we restrict to knowledge workers (roughly, jobs that can be done on a laptop), these dates move even closer.”
“My numbers would be lower by 1–3 years if the question were just about computer jobs. I expect the development of robots to be the limiting factor for reaching >90%.”
“I understand the question to state that a system exists capable of automating the vast majority of roles, and I feel that many of the arguments for slower timelines (around takeoff, rather than AGI) revolve around a slow pace of diffusion and unhobbling required to actually distribute those capabilities throughout the economy.”
Relationship between timelines and risk
There is a weak negative correlation (r = −0.25) between AGI timeline estimates and existential risk estimates: those with shorter timelines tend to assign higher existential risk, though the relationship is noisy.
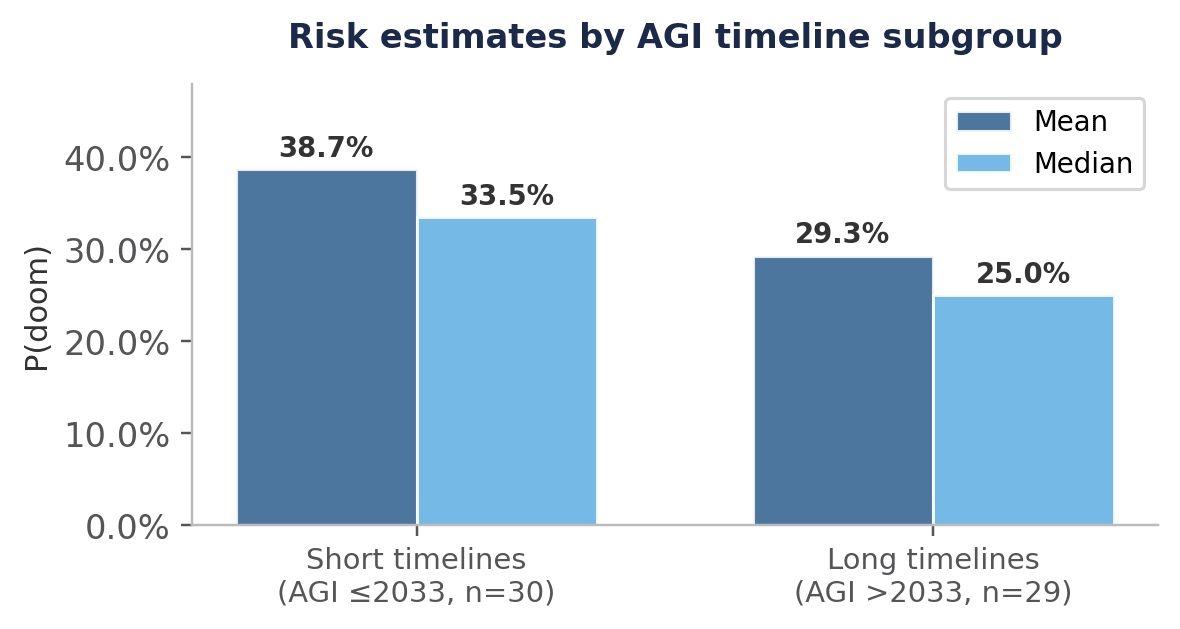
This subgroup difference is more pronounced when examining resource allocation preferences for misaligned AI, as discussed in the next section.
Resource allocation priorities
Respondents were asked:
On the current margin, should the community tackling x-risks direct more or less resources towards addressing the following risk categories and fields?
Below, we represent answers on a five-point scale from ‘Much less’ (−2) to ‘Much more’ (+2).
Overall preferences
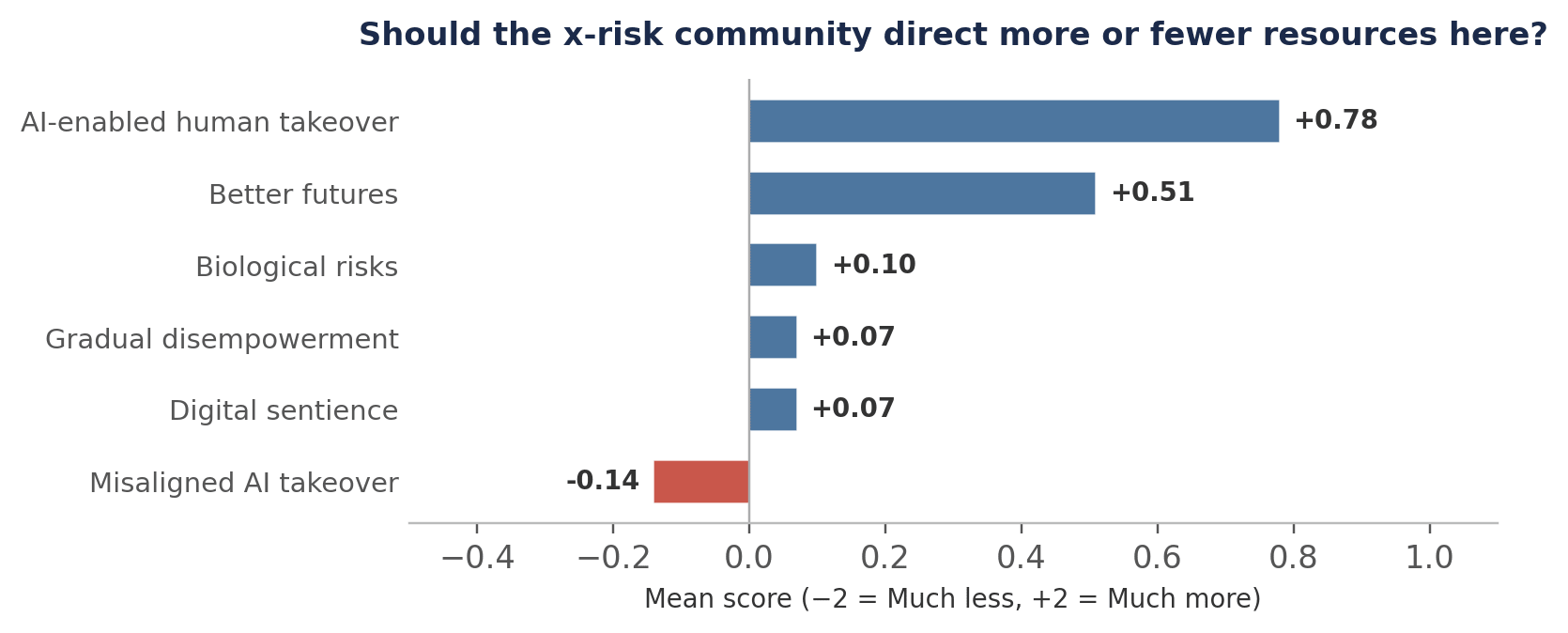
The clearest signal is the strong preference for more resources on AI-enabled human takeover (e.g. permanent authoritarian state scenarios), with 73% of respondents saying ‘More’ or ‘Much more’. Better futures work also received net-positive support. The slight lean against misaligned AI takeover resources is perhaps the most surprising result for this audience, and merits closer examination.
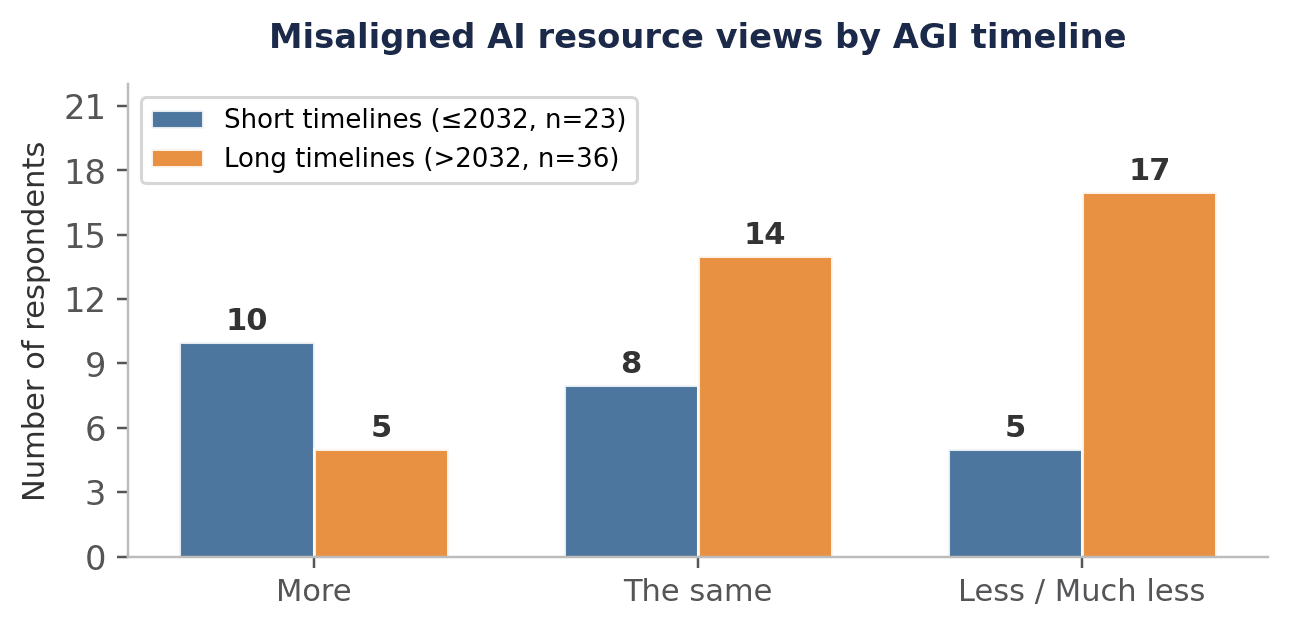
Misaligned AI views by timeline subgroup
The aggregate result on misaligned AI masks a significant divergence between subgroups. Among those with shorter AGI timelines (≤2032), opinion leans towards more resources; among those with longer timelines (>2032), it leans substantially towards fewer.
Notable comments
“I would carve out an AI slowdown/pause/moratorium as a category of its own, and assign it ‘much more’. I completely agree that it’s a heavy lift, but that’s offset by how fragile all the full-speed-ahead alternatives look.”
“AI-enabled bioterrorism is the one most likely to be handled in the near term by natsec, and so less of our resources and attention should be spent on that, relative to the authoritarian state risks which are more [sic] likely to come from natsec.”
“I rated AI-enabled human takeover in the ‘More’ category because I think this is an important threat and potentially more legible to politicians and the public, and digital sentience as ‘More’ because this seems to be the most confused outstanding space.”
“I think that all of these issues are extremely important and deserve much more support than they currently receive, so my answers here focus primarily on which ones seem most neglected.”
“I see digital sentience / model welfare as a subset of better futures.”
Sub-field priorities
Respondents were asked:
Which of these sub-fields do you think is most important to direct significantly more resources to?
They could select up to three sub-fields. Out of 58 respondents:
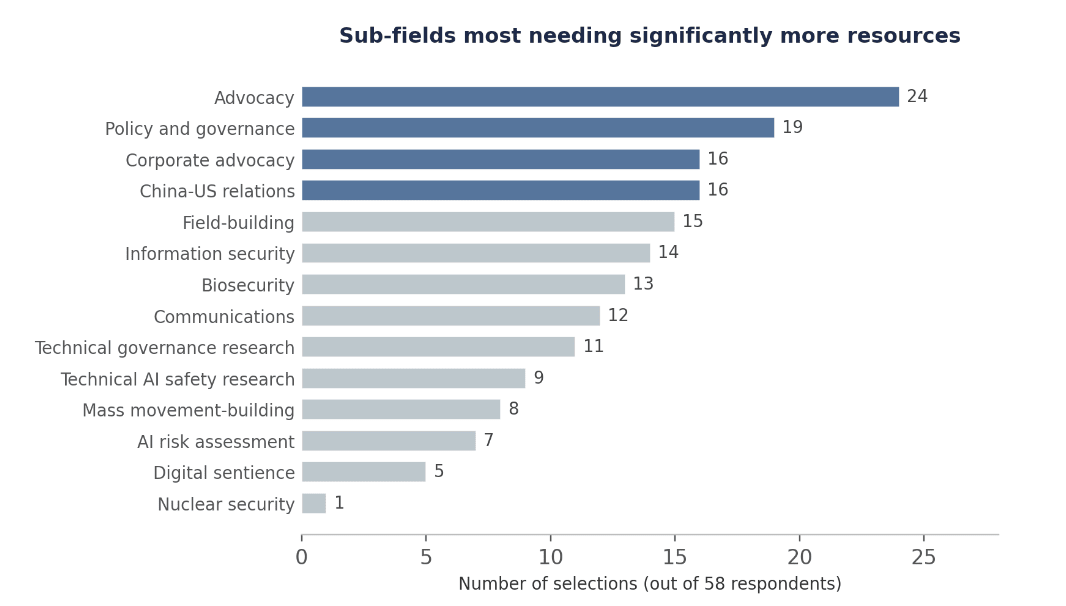
The top tier of sub-fields (advocacy, policy and governance, corporate advocacy, and China-US relations) are all oriented towards institutional engagement rather than technical research. Technical AI safety research is selected by only 15% of respondents, ranking 10th of 14 options.
Notable comments
“My chosen sub-fields fall from my thesis that one of the most important things we can do is lay the groundwork such that a non-existential crisis / ‘shot across the bow’, if it occurs, leads to maximal positive action and societal response. I suspect the following course of events will be highly sensitive to initial conditions, and thus this is the type of space where concerted action from those in this community could do a lot of good.”
“This question is highly contingent on who’s giving the money and how it’s being dispersed! I think China-US relations are highly important. I think field-building targeted at more experienced people who can go on to start and lead competent organisations (and who have networks to convert a load of other experienced people) is much more important than more junior field-building. I think most existing AI safety fellowships act as internship programmes for the labs, which is fine, but we should be doing more than that.”
“Information security, biosecurity, and nuclear security seem like the paths to avoiding takeover risk.”
Areas of consensus and debate at the event
This section summarises common themes from attendee-written memos shared at the Summit.
Areas of broad consensus
Talent, not funding, is currently the binding constraint on the AI safety field.
Current safety frameworks and evaluation practices are necessary but insufficient. There was widespread agreement that voluntary safety commitments need stronger governance structures, independent oversight, and systematic transparency.
Risks from aligned AI (power concentration, lock-in, authoritarian entrenchment) could be equally important to alignment and deserve much more attention from the AI safety community than they're currently receiving.
Attendee memos proposed crisis action plans, post-AGI scenario exercises, and resilience infrastructure, reflecting a broad consensus that being ready for multiple futures matters more than predicting which one arrives.
AI character and identity are being shaped now, mostly unreflectively. Multiple memos argue this is an under-attended parameter with large downstream consequences.
Areas of active debate
Timelines and risk levels. Disagreements here are largely captured in the above survey results.
How well is alignment going? Some attendees think that alignment could be solvable and that concerning signals in RL-trained models have been substantially mitigated. Others hold that current models are meaningfully misaligned and that this would be existentially dangerous at greater capability levels.
Is automated alignment research a plan or a prediction? Some memos treat it as a viable strategy; others question whether it contains anything differential that distinguishes it from “build a superintelligence and hope for the best.”
- ^
We recognize this represents a form of sampling bias above and beyond those who attended the summit.
Just wanted to flag the group is heavily selected for belief alignment with something like "EA/Constellation/Trajan House" views, and "AI enabled human takeovers" was promoted as agenda to prioritize in multiple widely read memos by high statues people in the community (which the organisers prioritized in the reading list).
I dislike the "echo chambre" effect where the steps are:
- invite people partially based on alignment with the idea cluster
- tell them to read memos advocating something written by some of the most central people in the cluster
- poll attendees
- results are framed as "leaders and key thinkers in the x-risk and AI safety communities agree"
It is in some sense useful, but in my view the cluster of people invited represents maybe ~30% of thinking about x-risk and AI safety, and its mostly an amplification of existing voices.
"The slight lean against misaligned AI takeover resources is perhaps the most surprising result for this audience, and merits closer examination."
This is unsurprising given the marginal and somewhat confusing nature of the question. My wild guess is
- some attendees voted for everything; it is unclear what does it mean on the margin, probably to grow everything, and prioritize more neglected topics?
- some attendees understood the marginal question as "assuming fixed pie, how to change the allocation" - with this understanding you need to assign something negative weight for consistency
Thanks Jan, I appreciate the pushback.
As an event focused on x-risk, yes, I think this is fair.
It's true that:
But I don’t think attendees were as strongly influenced as you seem to imply:
I do think you're pointing to a real effect to be aware of, and thanks for pointing it out, but I don't think it's as significant as you make out (though maybe you don't think it's super significant).
I think the areas of broad consensus accurately (if roughly) reflect the data we have here and what we saw in memos. FWIW, my overall takeaway from running this survey is that leaders and key thinkers have a wide range of views and I think this post captures and conveys this.
This seems like a misinterpretation of Jan's point. There are multiple intellectual clusters which at least claim to care about x-risk which aren't well-described as the "EA/Constellation/Trajan House" cluster. The main ones which come to mind are:
I would only describe a few people in each cluster as actual thought leaders or key thinkers. So compared with Jan my concern is less about who gets invited, and more that sampling any gathering as large as the Summit averages together responses from people with too wide a range of levels of leadership to be accurately described as "AI safety leaders".
In case it's helpful: as an attendee of this event I would say ~2.5 of these 5 were like "decently" represented (not saying that's sufficient)
Yeah, I expected as much. Though as per my comment above, I'm much more concerned about representation of thought leaders. A better proxy for intellectual diversity is something like "are the few people from each of these clusters who are the biggest critics of the consensus view invited?" E.g. for the Pause AI cluster that'd probably be Holly; for the MIRI cluster that'd probably be Yudkowsky and Habryka; for the academic ML cluster that'd probably be Dan Hendrycks; for the sociopolitical safety cluster that'd probably be Ben Hoffman and Michael Vassar.
I don't know exactly who was invited but I expect that the Summit gets a medium score on this metric: not great, not terrible.
What is the 2026 "Summit on Existential Security"? When I look it up (in quotes), this article is the only result. I did find some stuff about a 2023 Summit on Existential Security but nothing from any other year. Is this something that happened at EA Global?
I don't put much credence in anonymous AI safety "experts", for reasons I elaborated on here.
It's a separate event run by CEA, which, in contrast to EAG, is much smaller and just for leaders in the field of xrisk. (I haven't been, but my wife attended this 2026 edition)
See also https://forum.effectivealtruism.org/posts/WLZabqQGCd2joZpxR/summit-on-existential-security-2023
You correctly point out that "AI safety leaders" is a group that selects for high concern about AI, which means that the average is skewed towards high concern, relative to experts more generally.
I would like to add that the same is probably true (to a lesser extent) for AGI timeline estimates: People that think that AGI is very far away are less likely to think that AI safety is a pressing concern and are thus less motivated to become AI safety leaders. Also, people who are concerned about present-day AI risks, but don't think AGI is imminent often call themselves "AI ethicists", rather than AI safety people. These "AI ethicists" are unlikely to show up to a "summit on existential security".
To be clear, I think it's good to write this article, but we should always be mindful of selection effects when interpreting surveys.
Thanks for the comment, titotal. I agree the survey underestimates the variance in AI timelines and risk.
The AI Futures, which is know for AI 2027, had super broad timelines for artificial superintelligence (ASI) timelines on January 26. The difference between the 90th and 10th percentile was 168 years for Daniel Kokotajlo (2027 to 2195), and 137 years for Eli Lifland (2028 to 2165).
There is also huge variation in assessment of AI extinction risk. In the Existential Risk Persuasion Tournament (XPT), among domain experts and superforecasters, the 5th and 95th percentile AI extinction risk from 2023 to 2100 were 9.45*10^-7 and 37.0 % (excluding the 7 people who guessed a risk of exactly 0; here are the results).
Note that that is a different kind of distribution (one person's beliefs) than the one reported here (many people's medians)
Hi Buck. True. I still think the survey underestimates the variance in median AI timelines. Below are the results for the 2023 Expert Survey on Progress in AI (ESPAI). Half of the responses for the median date of full automation of tasks or occupations range from around 2045 to some date after 2120. In the survery of the post, half of the responses for the median date of AGI range from around 2032 to 2037. For the 25th percentile date of full automation, half of ESPAI's responses range from around 2030 to 2100. In the survey of the post, half of the responses for the 25th percentile date of AGI range from around 2028 to 2032. AGI in the survey of the post does not have the exact same meaning as full automation of taks or occupations, but I am pretty confident my broad point stands if I am reading the graph below correctly.
Some vague questions are worth answering if they surface Information, but when the distribution is extremely broad, we should react epistemically with an update to the questions. From ESPAI23 to SES26 I see that being the case, where "all" becomes a more practical "90%", which appears to 10x reduce the timeline uncertainty as it pertains to respondents' 50% probability threshold.
Hi Emile. I see this is your 1st comment on the EA Forum. Welcome.
I think the difference in uncertainty is mostly explained by the surveys covering different people, not by ESPAI's predictions having been made around 2.25 years earlier. ESPAI 2023 involved "2,778 researchers who had published in top-tier artificial intelligence (AI) venues", and "took place in the fall of 2023". The 2026 Summit on Existential Security (SES) involved "leaders and key thinkers in the x-risk and AI safety communities", and "Survey data comes from the 59 respondents who consented to their answers being shared publicly", and "was collected in February 2026".
Buck, I would be curious to know what is your median time from weak AGI to artificial superintelligence (ASI) in this question from Metaculus, and your best guess for the (unconditional) probability of human extinction in the next 10 years.
I don't want to take the time to really understand the operationalizations used in that question, sorry—I'm worried that the answer might depend substantially on finicky details. In general I think that the AI Futures Model is pretty similar to my views on how long it will take to go from "weak AGI" to "ASI", for various definitions of those terms.
I think AI takeover in the next ten years is like 35% (😔), and conditional on takeover, I mostly agree with this; AI takeover is the main mechanism that causes me to expect massive human fatalities in the next decade.
Got it. Thanks. Here is what @Ryan Greenblatt says in the piece you linked about fatalities from AI takeover.
Ryan, could you clarify what is the timeline for the 50 % of humans dying in expectation conditional on takeover?
The 25 % chance of human extinction refers to the 300 years following takeover, and excludes voluntary informed extinction, which I like because it would not be obviously bad. Here is footnote 4.
Very enlightening. I'm most interested in the following excerpts:
1: Talent, not funding, is currently the binding constraint on the AI safety field.
2. I think field-building targeted at more experienced people who can go on to start and lead competent organisations (and who have networks to convert a load of other experienced people) is much more important than more junior field-building. I think most existing AI safety fellowships act as internship programmes for the labs, which is fine, but we should be doing more than that.
I'm wondering what specifically are the talents needed to start and lead competent organisations in this space? What gaps are there between existing orgs? And is that the only kind of talent that is constraining the AI safety field?