
Recently, a growing group of EAs, EA-adjacents, post-EAs and EA-curious folk have been gathering and organising around a new term - integral altruism (int/a). The central claims of int/a are that the EA toolkit is powerful but incomplete, and that EA can learn from other movements who are trying to improve the world.
The goal of int/a is to find a broader approach to altruism by integrating EA with epistemics/ontologies/world models/language/culture from outside of the EA/rationalist bubble. More specifically, we reckon EA can be most constructively complemented by learning from movements, communities and thinkers who emphasise wisdom. Accordingly, our intellectual lineage is a combination of EA/rationalism and the liminal/metamodern/metacrisis world.
We’ve run a whole bunch of events of various flavours and have plans for more. These included residential retreats, reading/discussion groups (e.g.), a speaker series (e.g.), deliberative technology experiments (e.g.), workshops (e.g.), hackathons (e.g.), and more. In the future we’d love to try running more ambitious projects like conferences, incubators, or fellowships. We’re currently looking for funding.
What is this for?
There are many of us who want to improve the world but feel that EA in its current form is unable to sustainably support us to cultivate and practice altruism. Some common reasons for this are
- An exclusive focus on a narrow range of cause areas (e.g. the coalescing around AI safety), in tension with radical uncertainty & cluelessness,[1]
- A lack of trust in epistemic tools outside of formal rationality (like intuition, metarationality, ecological rationality, Vervaeke’s 4Ps, or The Heart™),
- An action bias that may be leading to negative effects (like exacerbating the AI race or the whole FTX drama),
- An underemphasis in systems change as a cause area,
- A culture that can result in unsustainable personal sacrifices leading to burnout,
- A shadow side of the movement (e.g. status-seeking, power-seeking, guilt-escaping) that may be messing with collective epistemics.
A common theme linking all of these issues is a desire for more wisdom. By wisdom we mean[2] recognising the limits of our own knowledge, awareness of context, perspective-taking, and careful consideration of how to balance or integrate different viewpoints and interests.
A core motivation for more wisdom is recognising that we are radically uncertain[3] about the problems we’re trying to solve and the more broad question of how to do good. Such radical uncertainty calls for a more careful, robust, and flexible portfolio of frames/tools/approaches.[4]
In the EA context, wisdom caches out as seeing EA as not the one-and-only but one of a number of frameworks for changemaking that can be integrated to produce something more robust. This means letting go of the search for a scientific “view from nowhere” on how to solve the problem of altruism, and being aware of the cultural conditioning that lies behind any framework for doing good. It also means making space for other values besides “maximize impact”.[5]
int/a’s goal is to create a new network, culture, and formal(ish) framework that supports those of us who take radical uncertainty seriously and desire this broader view on altruism to become the best versions of ourselves and do our part in bringing about a flourishing future.
The (tentative) integral altruism principles
At the first int/a summit in summer 2025, we ran a workshop aimed at attempting to more clearly define integral altruism. The result was a set of principles we would like to embody and guide us in doing good.
Thanks to Aaron Halpern, Ben R. Smith, Brayden Beckius, Christine Tan, Elisa Paka, Finn Clancy, Gamithra Marga, Georgie Nightingall, Jon Hall, Katie Calvert, Luke Fortmann, Matilda du Rui, Patrick Gruban, Plex, Tildy Stokes and Toby Jolly for their Very Sensible And Quite Profound contributions.
We intend the presentation here to be descriptive rather than convincing - arguing for the merits of these principles is beyond the scope of this post (we may publish arguments in a future post!).
The principles are not final; we expect our understanding of this space to evolve over time. The principles are also currently somewhat abstract, in the future we hope to translate these to be more concrete & action-guiding. With those caveats out of the way, here is what we came up with.
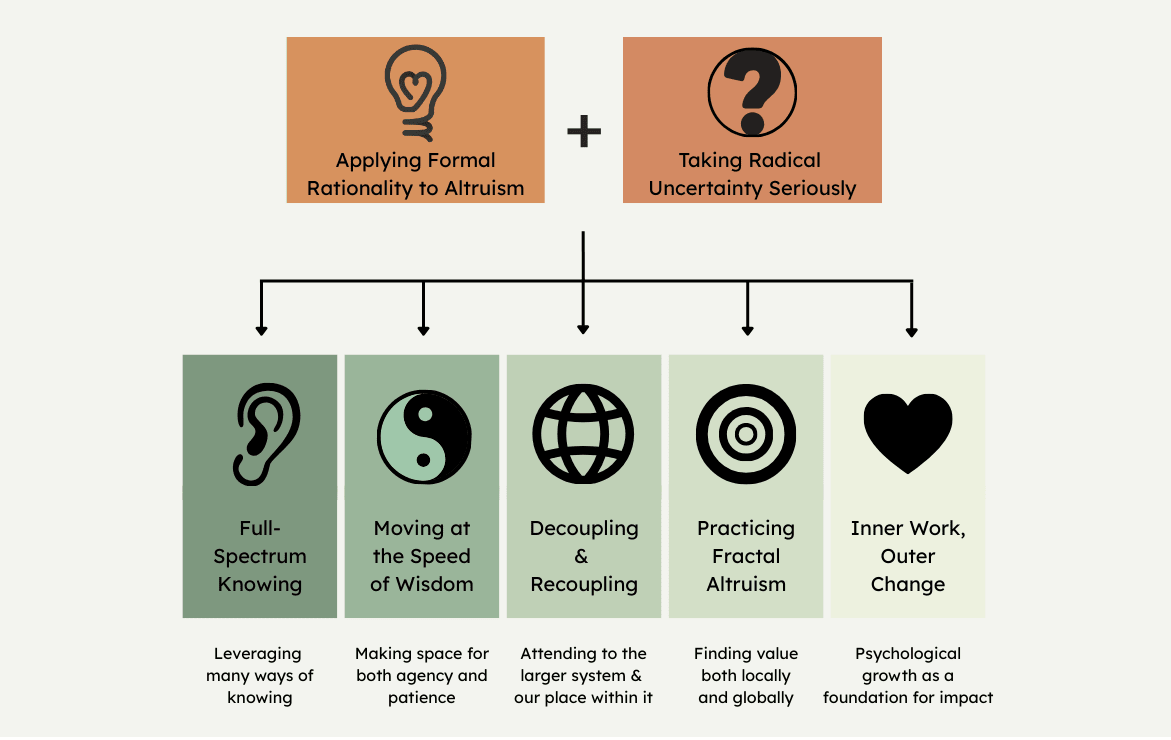
1. Full-Spectrum Knowing
We want to integrate EA’s rigorous, grounded, rational epistemics with other valuable ways of knowing like embodied intuition, ecological rationality, or Vervaeke’s 4Ps.
This comes from recognising the limits of formal rationality in taking effective action in the real world, and seeing that reason & evidence is not sufficient for attuning to what is most important. It means taking other forms of knowing seriously but also knowing when to use them.[6] It means listening to all parts of ourselves, resulting in action that is internally aligned and authentic.
In practice, this could mean
- Experimenting with including the 4Ps in discussions,
- Augmenting decision-making with meditative (e.g. mindfulness), contemplative (e.g. journaling), embodiment (e.g. focusing), relational (e.g. collective insight), or dialogical (e.g. socratic questioning) practices.
- Applying integration practices (like IFS or core transformation) to our altruistic goals.
There’s a thread you follow. It goes among
things that change. But it doesn’t change.
People wonder about what you are pursuing.
You have to explain about the thread.
But it is hard for others to see.
While you hold it you can’t get lost.
Tragedies happen; people get hurt
or die; and you suffer and get old.
Nothing you do can stop time’s unfolding.
You don’t ever let go of the thread.
(William Stafford)
2. Moving at the Speed of Wisdom
We want to integrate EA’s action-oriented energy with discernment of when to take high-impact actions and when to wait until the next graceful move reveals itself.
In other words, this means integrating the yin and the yang. Letting go of the need to control everything and transcending the frame that we are in conflict with the natural unfolding of the universe. This also means emphasising collective action over individual heroism.
In practice, this could mean
- Generally seeking stakeholder input before taking high-impact actions,
- Avoiding unnecessarily power-seeking moves on a both personal (e.g. climbing to the top of orgs) and collective (e.g. founding AI labs and racing to the front) level,
- Emphasising process-orientation over goal-orientation.
You thought, as a boy, that a mage is one who can do anything.
So I thought, once. So did we all.
And the truth is that as a man’s real power grows and his
knowledge widens, ever the way he can follow grows narrower:
until at last he chooses nothing,
but does only and wholly what he must do…
(Ursula K. Le Guin)
3. Decoupling & Recoupling
We want to embrace EA’s analytical & decoupling approach of isolating the most important problems while also attending to the larger system & our place within it.
Different cause areas and x-risks are highly interconnected. While decoupling problems from their context can be useful for making progress, it can also make us blind to this entanglement. We want to adopt both decoupled frames and contextualizing frames (like the metacrisis).[7]
This also means seeing our place within the system: Maintaining awareness of the assumptions underpinning the cultural paradigm we are operating in (e.g. capitalism, colonialism, techno-solutionism, or victim/oppressor narratives).
In practice, this could mean
- Using tools from systems thinking & complexity science,
- Taking systems change & cultural change seriously as cause areas,
- Creating cross-cultural fellowships in epistemically distant communities.
There is no such thing as a single-issue struggle
because we do not live single-issue lives.
(Audre Lorde)
4. Practicing Fractal Altruism
We want to balance EA’s scope-sensitive ambition to work towards the largest positive impact with intrinsic values at the local scale like friendship, love, beauty, family and the sacred.
This means being good to ourselves and the people around us as well as the rest of the world. It doesn’t mean forgetting about impact, but rather finding ways to cooperatively integrate scope-sensitive altruism with other ends in one’s life by imaginatively searching for win-wins between these ends.
In practice, this could mean
- An empathetic approach to career paths that takes into account not only effectiveness but how that work can enhance one’s own life,
- Running events that simultaneously nourish individuals, cultivate deep connections, and lead to impact at scale,
- Explicitly & honestly examining which tradeoffs between personal, community and global goods we are willing to make.
Start close in,
don’t take the second step
or the third,
start with the first
thing
close in,
the step
you don’t want to take.
(David Whyte)
5. Inner Work, Outer Change
We want to integrate EA’s culture of supporting one’s intellectual, productive and career growth, while also supporting psychological growth as a foundation for impact.
Psychological, emotional and spiritual development can help us cultivate a genuine desire for the wellbeing of others, resulting in altruism grounded in truth rather than being driven by guilt or pride. Such growth can also improve our epistemics by shining light on What’s Going On For Us and inspire action by deeply connecting us to the value we’re fighting for.
In practice, this could look like
- Using practices like metta meditation to cultivate our altruistic drive,
- Collective shadow work on the topic of altruism (like this event),
- Tracking our growth using frameworks like the Inner Development Goals.
I slept and dreamt that life was joy.
I awoke and saw that life was service.
I acted and behold, service was joy.
(Rabindranath Tagore)
Putting this all together, integral altruism is a community for those who want to help improve the world in a way that is effective, wise, and sustainable - by integrating reason with embodiment, agency with patience, decoupling with contextualizing, impartial values with local values, and inner work with outer change.
What’s happening?
We’re experimenting with a number of flavours of events in order to cultivate the community and create a space for the int/a framework to develop. Our main physical hub is London, with nascent communities springing up in Berlin and Paris.

Some experiments we’ve run so far are
- Residential retreats (/“summits”) where the most engaged members can grow as altruists, deepen our community and make progress on the int/a framework,
- Reading/discussion groups (on topics like Moloch, critiques of Bayesianism, and ecological rationality),
- Deliberative technology experiments (like antidebates and collective insight),
- An online speaker series (on topics like metacrisis & AI governance, the history of post-rationality, and cultural evolution),
- Wisdom development circles & work integration circles,
- Writing & synthesis hackathons (e.g.),
- Cause X scanning,
- Funky new relational practices,
- Tabletop roleplaying exercises.
And we have a big list of other ideas (like conferences and intro courses) we’d like to put into motion.
The conceptual development of the int/a framework is slowly happening but is still in its early days. We recently ran a frameworks hackathon, you can check out some of the ideas that came out of that here.
We have a core of engaged people running the show: six “core stewards” (currently Christine Tan, Patrick Gruban, Tildy Stokes, Toby Jolly, Finn Clancy, Euan McLean). We’ve implemented some governance structure that we’re slowly testing and evolving.
Our intended relationship with effective altruism
We’d love int/a to have a symbiotic relationship with EA. We reckon int/a’s goals are win-win with EA’s goals in a number of ways:
- Being a place to help those who have drifted away from EA to reconnect with their altruistic nature and put that into practice once more,[8]
- Generating constructive dialogue with the EA philosophy, and red-team EA as a movement,
- Creating a bridge between EA and other movements, resulting in useful knowledge exchange, especially introducing more wisdom to EA.
That being said, we’re also aware of the danger of potential zero-sum dynamics between int/a and EA, and would like to avoid them as much as possible. One thing we are afraid of is int/a gravitating towards the “just bitching about EA” attractor state, which is definitely not the vibe we’re going for. Another concern is “taking people away from EA”. We don’t intend to dissuade people from doing impactful work by EA lights, in fact many of us in the movement are doing incredibly canonical EA jobs.
Wanna get involved?
If you’re intrigued or excited about this general direction, you can register your interest for getting involved here, keep an eye out for future events, and subscribe to our substack.
We’re also currently looking for funding since we’re severely funding constrained. If you'd like to support int/a to grow, or know someone who might, you can find our funding page here.
Thanks to Chris Pang, Christine Tan, Elisa Paka, Gamithra Marga, Georgie Nightinghall, Guillaume Corlouer, Hunter Muir, Jack Kock, Jonah Wilberg, Patrick Gruban, Simon Haberfellner, and Toby Jolly for feedback on early drafts.
- Which can lead to those who are drawn to other cause areas becoming alienated from the community. ↩︎
- Wisdom is a highly nebulous concept and is used in a number of different ways. To gain some precision, we used a definition of wisdom above based on the work of Igor Grossman, one of the leading wisdom scientists. Grossman identified a central component of wisdom to be persectival metacognition - which caches out as the definition we give here. ↩︎
- In the book Radical Uncertainty, Mervyn King & John Kay define radical uncertainty to be when a situation is unresolvable by further research in principle, where we cannot enumerate the range of possible options or futures, and where previously inconceivable events can emerge. ↩︎
- See Jonah Wilberg’s article for more on how radical uncertainty calls for wisdom. ↩︎
- According to Logan Strohl’s model of EA burnout: “EA burnout usually results from prolonged dedication to satisfying the values you think you should have, while neglecting the values you actually have.” By creating a space that supports the integration of different values, int/a can support people to sustainably engage with EA work. ↩︎
- For example, we don’t want this to be an excuse to throw all science & rationality away in favour of just going with our emotions - we want to understand the strengths of both and know what kinds of questions call for one over the other. ↩︎
- While “zoomed out” frames can lead to compromise on tractability, we would like to make explicit the tradeoff between tractability and better epistemics (via seeing more of the system) rather than just automatically attending to the decoupled frame. ↩︎
- See footnote 5. ↩︎
I appreciate the efforts to try and bridge two projects you think are valuable. A few thoughts/comments/disagreements:
1. One way to read this seems to me like it could boil down to: if you like EA, but also want some more metacrisis/sensemaking/systems thinking than what EA typically offers, then that's us. Come say hi.
2. I feel like there's some irony here where EA conversation norms tend towards very direct communication, and sensemaking folks tend to speak in a more indirect way. In pitching integral altruism I can't help but get the feeling it is framed in fairly indirect language at times. It's hard to name the exact dynamic but I found myself working hard to understand parts of what this paragraph is trying to say (maybe that's just me):
3. Some of these points seem surprising to include as what is added by integral altruism as they seem to me as a regular part of EA discourse. I'm thinking about the sections that discuss valuing other things in life besides impact, and that inner work can lead to more impact.
4. I think a big decision point here is whether or not the merits of integral altruism will be argued on the territory of EA assumptions or not, and this post seems to move between the two. For example, you make the claim that there are real downsides to seeing x-risk in isolation rather than in the way it is interconnected with other problems. This seems big and important if true, and seems like something that could be argued comfortably within the framework of EA norms. I appreciate that puts the burden on you, but if you persuade folks here, I imagine that would be a big win for everyone. FWIW whenever I've listened to folks talk about the metacrisis I've literally not been able to understand the arguments. Could be a huge service to try and make the case for the metacrisis in EA friendly language.
Thanks for the thoughtful response Elliot!
On point 2 - yes, it is a fair criticism of both int/a and the sensemaking folks that what we're saying feel indirect. The challenge as I see it is that the things the sensemaking world are pointing at are just a lot harder to put in very explicit terms. That doesn't necessarily mean stuff like the metacrisis doesn't exist, it could just mean that its harder to point at/analyze/get traction on.
I've heard metacrisis people describe EA as 'searching for the keys under the lamppost', in that EA focuses on the things that can be explicitly stated and modeled, which is not necessarily the same as the set of problems that exist. They would argue that instead of continuing to search under the lamppost, maybe we should build new lampposts, or buy a torch, or whatever. I don't fully condone this but it's a good intuition pump for where they're coming from.
Part of int/a's ambition in building this bridge is to try to caste sensemaking ideas in more direct EA-brained terms (like this rough first attempt), but it's tough and a work in progress!
On point 3 - sure, a lot of what we talk about here is already in the EA discourse to varying degrees. I think the distinction is the degree in which the value is emphasized and practiced. For example, the element of 'personal fit' is a meme that exists within EA, but in the 80k guide feels like a footnote. In contrast, in int/a we have an intention for personal fit to be quite central and have it inform the structure and emergent behavior of the movement.
On point 4 - yea great point. Ultimately it would be cool to examine whether int/a makes sense on both EA territory and other territories.
I'm really pleased to see so many people coalescing around this post. I'm enormously blessed to be amongst people thinking about the big problems with such openness, passion, and energy.
Int/a correctly identifies that EA has imperfections. But the proposals, replacing specificity with multidimensionality, putting process over goals, substituting metrics with sensing, don't fix those imperfections. They mostly obfuscate them by disallowing comparison and avoid failure by never choosing between options. I think the main problem int/a has with EA is not an EA problem but an imperfect-world problem.
EA's singleminded focus on specificity, measurability, and goal-orientedness is the painful, imperfect method that turns values and caring and messy big problems into singular choices and actions. Yes, the metrics are always flawed. Yes, you cut off possibilities when you commit to a direction. That's the cost of actually acting in the world, and I don't think int/a has provided a better path forward.
I may be being ungenerous, but my aim is to cut through to my biggest concern and look for correction. What int/a offers is staying in the ideation phase. More intuition, more holism, more systems thinking, more openness, more frames. Every single recommendation is widening, sourcing, and uncontroversial. These are a vital part of the opening process. But as far as I can tell, int/a does not move past enriching understanding, and does not seem concerned with what that is giving up. At some point the unpleasant part has to come: splitting apart, letting go of options, committing to something that might be wrong. EA isn't limiting itself to specificity and comparison out of compulsion. It sees these as necessary stages. Pleading for more modalities does not get you to a tradeoff-free world! At some point you have to demonstrate a better outcome.
The complexity science and metacrisis communities have said "see the whole system, keep entanglements, don't reduce" and then hit the entirely predictable problem of being unable to make much headway. They have produced real analytical tools, but the endpoint actions remain sparse. Is EA's predisposition towards action more harmful than int/a's moving at the speed of wisdom? I genuinely think EA's greater bias toward action has produced more good than harm. But I can see arguing for change.
What int/a does do well, and EA should listen to, is their unearthing root problems, catching incomplete definitions, calls for opening up, and providing more frames. Int/a can teach us greater things to get narrowed toward. I don't think its best seen as a competing method. It needs to be handed off to EA-style problem-solving, and should be resurfaced periodically too.
I strongly disliked this post for reasons that I'm not sure how to articulate. It seems to be advocating for a sort of lack of grounding in cost-effectiveness that is the thing that makes EA good. Or maybe my issue is that this post advocates for things that are difficult to disagree with ("full-spectrum knowing"; "wisdom"), without acknowledging tradeoffs (why do EAs allegedly not put enough priority on full-spectrum knowing?) or not saying anything concrete about how EAs could do more good.
[edited to be more polite]
I don't think they are trying to convert the EA community into something else - they are pretty clearly creating separate spaces for their movement/community. [1]
Describing their post as using "applause lights" seems at best uncharitable, and "absolute nonsense" is just rude. There are several well-received posts on the forum around "[a]ugmenting decision-making with meditative (e.g. mindfulness) [practices]" like this one and this one. It's fine to dislike their principles, but I think it's worth making an effort to be encouraging when fellow altruists try to build on the "project" of Effective Altruism;.
e.g. they say "That being said, we’re also aware of the danger of potential zero-sum dynamics between int/a and EA, and would like to avoid them as much as possible. One thing we are afraid of is int/a gravitating towards the “just bitching about EA” attractor state, which is definitely not the vibe we’re going for. Another concern is “taking people away from EA”. We don’t intend to dissuade people from doing impactful work by EA lights, in fact many of us in the movement are doing incredibly canonical EA jobs." and have run many events themselves under their own banner.
You're right, I was unnecessarily hostile. I edited the comment to tone it down.
I can't speak for everyone associated with integral autism, but at least for myself I don't see it as about avoiding tradeoffs so much as about making tradeoffs against a wider set of considerations that are often left out by EAs. For example, I'm generally more willing to evaluate interventions in non-consequentialist terms since looking at the consequentialist framing only, as many EAs do, can lead to classic right-magnitude-wrong-direction errors that would be easily caught by a deontological or virtue ethics frame.
But in practice I expect int/a to make its own errors that will need correcting. One way someone I know put it, EA is fundamentally Protestant, int/a is fundamentally Buddhist. Both want to do good in the world, but each has a different view of what that world is.
Any examples of interventions EA might overlook that int/a rates highly in your view? (No need to speak for others)
I think it more often goes the other way, in that there are interventions that look good to EAs that look less good to int/a. For example, I'm relative negative on unconditional cash transfers, and I think most of the evidence showing they work is too narrowly scoped and fails to consider what happens to a society that is nicer only because of handouts and is failing to build a self-sustaining economic engine needed for the niceness to persist. I know some such programs are aware of this problem and try to address it, but it also leaves me feeling like there might be better solutions.
I guess on the other side maybe I'd say EA is by default too negative on arts charities. I'm not saying that your typical arts charity is effective, but I am saying I think it'd be a mistake if we reallocated all arts funding to top GiveWell charities, as access to museums is worth something even if it's hard to qualify against human lives (perhaps more generally, I think not all goods are actually as fungible as the typical EA thinks).
It's worth restating what I said in the post here:
And
Getting into more detailed arguments of what EA is missing and precisely what they should do differently is quite a big project due to the inferential difference between EA and liminal land, and one that I hope int/a can attempt in the future.
FWIW I think it's historically pretty incorrect that the grounding in cost-effectiveness is what made EA good. E.g. insofar as you think that AI safety is valuable, reasoning about cost-effectiveness actually cut against EA's ability to pivot towards that. Instead, the thing that helped most was something like intellectual openness.
Cost-effectiveness is precisely the reason why I focus on AI safety. I can only speak for myself but I think the same is true for a lot of people. The thing that cuts against AI safety is more like "rigorously measurable cost-effectiveness", but that's not what I mean by "cost-effectiveness". You can't give a precise cost-effectiveness estimate for AI safety work, but it's pretty easy to show that it's orders of magnitude more cost-effective than GiveDirectly on any plausible set of assumptions.*
*unless it's net negative, which unfortunately much EA-adjacent AI safety work turned out to be...but at least we can say that it's orders of magnitude higher absolute impact
IMO you should think of global health/factory farming etc as one paradigm of EA—which did focus on cost effectiveness—and AI safety as a different paradigm in which the concept of cost-effectiveness is simply not very useful, for a few reasons (see also this related comment):
Re "it's pretty easy to show that it's orders of magnitude more cost-effective than GiveDirectly": the kinds of reasoning that one might use to show that are pretty similar to e.g. the kinds that a communist could use to show that a proletarian revolution is orders of magnitude more cost-effective than GiveDirectly. In other words, it's mostly reasoning within the confines of a worldview, and then slapping on a "cost-effectiveness" framing at the end, rather than having the cost-effectiveness part of the reasoning be load-bearing in any meaningful way.
>I think it's historically pretty incorrect that the grounding in cost-effectiveness is what made EA good
FWIW the reasons you're giving here are closely related to the reasons why I'm sceptical that modern AI-focused EA is in fact as good. I don't think it's unreasonable to support AI safety work, but I think it's throwing away most of the epistemics that could make EA a long-term robustly positive influence. EA's original tagline used to be 'using evidence and reason', but the extreme AI safety focus seems to drop the 'evidence' part.
To believe you should focus on AI safety, you need to believe all of
and surely some further assumptions I've missed, and many ways to further unpack these premises. To advocate work on AI safety as the primary EA cause you need to believe that the final bullet applies to the majority of your audience.
But I think there's plenty in that list of assumptions that's easy to disagree with, and a lot of entangled assumptions whose entanglement to my knowledge hasn't really been explored (e.g. I find it hard to credit both that there's no convergence between intelligence and morality and that there's a long term equilibrium which is both stable and in some nontrivial sense positive or desirable).
So I semiagree with @MichaelDickens's original comment's in-principle scepticism while wondering whether in practice int/a might end up promoting causes that feel closer to the what I view as the original spirit of the movement.
There's also some practical concerns in the OP that I think EA has dropped the ball on, such as building the sort of real community that would have retained greater support/membership over the years (my impression is the substantial majority of EAs who joined the movement more than 6 or 7 years ago have largely disengaged with it).
So I guess I'm noncommittally hopeful that this becomes something valuable - and remains, and Euan said, symbiotic with EA. If it just gives people who would have been somewhat supportive but felt too constrained a way to stay engaged with an encouraging community, that seems like it could be high value.
In hindsight I shouldn't have used the phrase "what made EA good", since by this point I'm skeptical about both the AI safety version and the "original spirit" of EA. I guess that makes me one of the people you're describing who joined a long time ago (in my case, over a decade) and have now disengaged.
I do think that int/a is less likely than EA to be significantly harmful, and I'm excited about that. Whether or not it has a decent chance of actually doing something meaningful will depend a lot on the vision of the founders (and Euan in particular). Right now I'm not seeing what will prevent it from dissolving into the background of general hippie-adjacent things (kinda like a lot of the Game B and metacrisis stuff seems to have done). But we'll see.
I suspect whether it helped or hindered folks likely depends on where they were pre-EA. Did they need to learn to pay more or less attention to cost effectiveness?
Cool project :) There's definitely something very important in the rough direction you're pointing. Some thoughts on how to gain more clarity on it:
I filled in your form, and am excited to see where you take this!
I'd be interested in hearing more on what exactly you mean by this. Insofar as someone wants to make decisions based on impartially altruistic values, I think cluelessness is their problem, even if they don't make decisions by explicitly optimizing w.r.t. a model of the entire future. If such a person appeals to some heuristics or intuitions as justification for their decisions, then (as argued here) they need to say why those heuristics or intuitions reliably track impact on the impartial good. And the case for that looks pretty dubious to me.
(If you're rejecting the "make decisions based on impartially altruistic values" step, fair enough, though I think we'd do well to be explicit about that.)
Let's limit ourselves for a moment to someone who wants to make their own life go well. They have various instinctive responses that were ingrained in them by evolution—e.g. a disgust response to certain foods, or a sense of anger at certain behavior. Should they follow those instincts even when they don't know why evolution instilled them? Personally I think they often should, and that this is an example of rational non-model-based decision-making. (Note that this doesn't rely on them understanding evolution—even 1000 years ago they could have trusted that some process designed their body and mind to function well, despite radical uncertainty about what that process was.)
Now consider someone who wants to make the future of humanity go well. Similar, they have certain cooperative instincts ingrained in them—e.g. the instinct towards honesty. All else equal, it seems pretty reasonable to think that following them will help humanity to cooperate better, and that this will allow humanity to avoid internal conflict.
How does this relate to cluelessness? Mostly I don't really know what the term means, it's not something salient in my ontology. I don't feel clueless about how to have a good life, and I don't feel clueless about how the long-term future should be better, and these two things do in fact seem analogous. In both cases the idea of avoiding pointless internal conflict (and more generally, becoming wiser and more virtuous in other ways) seems pretty solidly good. (Also, the evolution thing isn't central, you have similar dynamics with e.g. intuitions you've learned at a subconscious level, or behaviors that you've learned via reinforcement.)
Another way of thinking about it is that, when you're a subagent within a larger agent, you can believe that "playing your role" within the larger agent is good even when the larger agent is too complex for you to model well (i.e. you have Knightian uncertainty about it).
And yet another way of thinking about it is "forward-chaining often works, even when you don't have a back-chained reason why you think it should work".
Thanks for explaining! To summarize, I think there are crucial disanalogies between the "make their own life go well" case and the "make the future of humanity go well" case:
In this case, the reasons to trust "that some process designed their body and mind to function well" are relatively strong. Because of how we're defining "well": an individual's survival in a not-too-extreme environment. Even if they don't understand evolution, they can think about how their instincts plausibly would’ve been honed on feedback relevant to this objective. And/or look at how other individuals (or their past self) have tended to survive when they trusted these kinds of instincts.[1]
Here, the reasons to trust that the instincts track the objective seem way weaker to me,[2] for all the reasons I discuss here: No feedback loops, radically unfamiliar circumstances due to the advent of ASI and the like, a track record of sign-flipping considerations. All else is really not equal.
You yourself have written about how the AIS movement arguably backfired hard, which I really appreciate! I expect that ex ante, people founding this movement told themselves: “All else equal, it seems pretty reasonable to think that trying to warn people of a source of x-risk, and encouraging research on how to prevent it, will help humanity avoid that x-risk.”
(I think analogous problems apply to your subagent and forward-chaining framings. They’re justified when the larger system provides feedback, or the forward steps have been validated in similar contexts — which we’re missing here.)
The way I use the term, you’re clueless about how to compare A vs. B, relative to your values, if: It seems arbitrary (upon reflection) to say A is better than, worse than, or exactly as good as B. And instead it seems we should consider A’s and B’s goodness incomparable.
What if someone has always been totally solitary, doesn’t understand evolution or feedback loops, and hasn’t made many decisions based on similar instincts? Seems like such a person wouldn’t have reasons to trust their instincts! They’d just be getting lucky.
See here for my reply to: “Sure, ‘way weaker’, but they’re still slightly better than chance right?” Tl;dr: This doesn’t work because the problem isn’t just noise that weakens the signal, it’s “it’s ambiguous what the direction of the signal even is”.
Hmm, I think you're overstating the disanalogy here. In the case of the individual life, you say "the reasons to trust "that some process designed their body and mind to function well" are relatively strong". But we also have strong reasons to trust that some process designed our cooperative instincts to allow groups of humans to cooperate effectively.
I also think that many individuals need to decide how to make their lives go well in pretty confusing circumstances. Imagine deciding whether to immigrate to America in the 1700s, or how to live in the shadow of the Cold War, or whether to genetically engineer your children. There's a lot of stuff that's unprecedented, and which you only get one shot at.
Re the experience of AI safety so far: I certainly do think that a bunch of actions taken by the AI safety movement have backfired. I also think that a bunch have succeeded. If you think of the AI safety movement as a young organism going through its adolescence, it's gaining a huge amount of experience from all of these interactions with the world—and the net value of the things that it's done so far may well be dominated by what updates it makes based on that experience.
I guess that's where we disagree. It seems like you think that we should update towards being clueless. Whereas I think we can extract a bunch of generalizable lessons that make us less clueless than we used to be—and one of those lessons is that many of these mistakes could have been prevented by using the right kinds of non-model-based decision-making.
EDIT: another way of trying to get at the crux: do you think that, if we had a theory of sociopolitics that was about as good as 20th-century economics, then we wouldn't be clueless about how to do sociopolitical interventions (like founding AI safety movements) effectively?
Richard's Why I'm not a Bayesian seems like a good starting point, as does this.
Thanks — I've read both but neither seems to answer my objection.
Thanks Richard!
On the 'hippies have too much agreeableness' point - yes, you are totally right!!
On the 'pinning down core int/a claims' point. I agree that in general getting more precise about claims is good. But I have some caution around pushing to generate precise object-level claims that "define int/a", in that you have to believe these claims to be part of it. One thing I feel towards EA is that it used to be about "the question" (how to do the most good), and created room for people to generate new answers to that question, but more recently it has become about "the answer" (this short list of career paths is how to do the most good). But I don't think the cultural/structural locking in of those answers is good because we might be missing crucial considerations that will only become clear in the future.
Yeah, I phrased it badly when I said that the movement should be pinning down claims. I'm not suggesting that you use these claims to define membership. Indeed, even the framing of your original post feels too "we are a group defined by believing the same things" for my taste (as compared with, say, "we're some collaborators with similar intellectual/emotional/ethical stances").
But I'm excited about you (and the others you mention in this post) writing about the things you personally think the EA worldview gets wrong, ideally not just engaging with how the movement turned out in practice but the broken philosophical assumptions that led to practical mistakes.
As one example, EAs constantly use "value-aligned" as a metric of who to ally with. But it seems pretty plausible to me that SBF was extremely value-aligned with most of the stated philosophical principles of EA. The problem was that he wasn't value-aligned with the background ethics of society that EA mostly takes for granted. Understanding this deeply enough I think would lead to you reconceptualize the whole concept of "value-aligned" towards things more reminiscent of int/a (in a way that would then have implications for e.g. what moral theories to believe, what alignment targets to aim AIs at, etc).
Thanks for writing this!
You're describing integral altruism as broader than EA, but if I understand you correctly, it's also narrower in many ways. Some examples:
–> Effective altruism doesn't take a position on whether we are in conflict with the natural unfolding of the universe. EAs emphasise collective actions vs. individual heroism to various degrees.
–> EAs already do this to various degrees. If integral altruists take this really seriously, they are a subset of EAs in this regard.
–> EA doesn't say where your altruistic motivation should be grounded in. All of the reasons you list are considered viable (although people of course disagree to what degree they are conducive/to be encouraged).
Some of the things you describe (especially the 'different ways of knowing') seem to sit more outside of what is common within EA. There it seems more like integral altruism actually is broader.
Overall I'm not completely sure whether integral altruism is a way of doing effective altruism differently, or a competing (though often overlapping) world view.
Thanks Tobias, some good threads to pull here!
Yes, the question of whether int/a is a subset of EA, overlapping, or something totally different has been a big point of discussion, and we haven't found a clean answer.
You are right that EA in some sense already contains a lot of the things int/a is excited about (especially in terms of the official written principles being quite broad), but perhaps the real difference is what is emphasized in practice.
For example:
Yea, EA doesn't explicitly say anything about that, but what we're pointing at is perhaps a cultural or semi-conscious current that pervades a lot of EA work (possibly this is more relevant to rationalism than EA). This line was inspired by in part by Joe Carlsmith's An Even Deeper Atheism, which points out a current underlying a lot of EA/rat/AI safety that is born out of a deep mistrust of everything (might not be doing the essay justice but that's the general direction).
I'm not necessarily saying this current is bad, rather that we should have an awareness of it and be able to step outside of that frame of mind when it is not helping us, and integrate different frames. The hope is that int/a can more explicitly/consciously find the right balance between the yang-y mistrusting the universe vibe and the yin-y trusting the universe vibe.