Defense in depth (DiD) is the idea that the best way to avoid a bad outcome is to spread your resources across several independent ‘layers’ of defense, rather than just building one layer of defense you think is super secure. I only ever hear DiD referred to positively, as something we should implement. This makes me suspicious: is it always a good idea? What are the relevant tradeoffs? In this post, I 1) More formally introduce DiD, 2) Make the case for DiD, 3) Consider when it might be counterproductive or less applicable, and 4) apply this to AI safety.
1. What is defense in depth?
Defense in depth originates from military strategy, so let’s start with that example. Suppose you don’t want your country’s capital to be invaded. The defense in depth thesis is that you are best off investing some resources from your limited military budget in many different defenses (e.g. nuclear deterrence; intelligence gathering and early warning systems; an air force, navy and army; command and communication bunkers; diplomacy and allies) rather than specialising heavily in just one.
In the case of AI safety, Hendrycks et al. propose such a multilayered defense approach.[1]
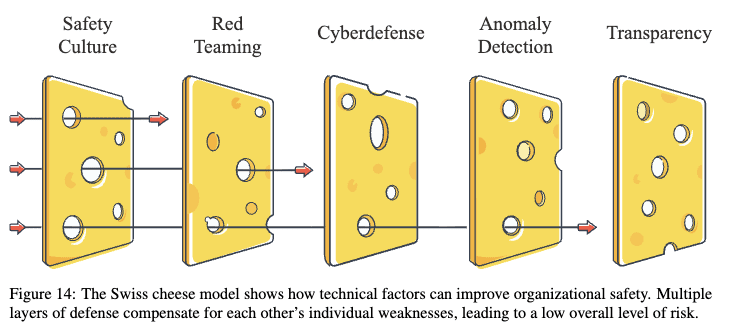
2. Why defense in depth?
There are several reasons to favour a DiD approach:
- There are often diminishing marginal returns to any single intervention/layer. E.g. a thousandth nuclear warhead is far less important for marginally improving deterrence than a tenth nuclear warhead. So picking ‘low-hanging fruit’ from several defensive layers may be more cost-effective.
- This is especially important if you want to deploy very large amounts of money relative to the size of the problem.
- Working across many layers allows you to productively deploy more types of resources, such as compute, political capital, talent, and money. E.g. in biosecurity, working across multiple layers and domains allows diverse skillsets in microbiology, engineering, ML, public health, modelling, policy, communications, etc to be useful. And automating safety work allows money and compute to be applied where that is more efficient than human talent.
- This is especially important if very many people are interested in contributing.
- If there are many independent threat models, then we may need separate layers defending against each. E.g. in biosecurity, just doing DNA synthesis screening or just doing zoonosis surveillance is insufficient, as that would miss either natural or human-caused pandemic agents.
- Humans are bad at making rigorous safety cases/proofs in real-world domains, so ‘hedging’ by not relying too much on any one line of defense is best. E.g. in cybersecurity, even code we have checked thoroughly and are confident doesn’t have any vulnerabilities may in fact be vulnerable via a zero-day exploit or other unknown unknown.
- Even if a particular layer is unlikely to fully stop a threat vector, it may delay an adversary, alert you that an attack is happening, and increase the costs of an attack, thereby buying time for other defenses, and depleting an attacker’s resources. E.g. defensive outposts may be unlikely to stop an invading army, but they could cause delay and provide useful information for the main lines of defense.
3. Why not defense in depth?
Here are some reasons not to favour DiD in some cases:
- If multiple layers are strongly correlated, they do not provide as much additional protection. E.g. if all the alarms, cameras, digital locks, and so forth in a security system are reliant on a single power supply, this creates a single point of correlated failure.
Relatedly, in cases where the threat is from an intelligent adversary (rather than a natural threat), the adversary may be able to go around or through all layers below some level of robustness, so any single highly secure layer would be preferable. An intelligent adversary can probe all defensive layers, and target their attack to the weakest point of each layer (swerving through the holes in the swiss cheese, in the figure below).[2] Indeed, an attacker at a sufficient capability level may be able to overcome an arbitrary number of weaker defensive layers for very little extra effort. E.g. no amount of consumer-grade firewalls and anti-virus software and access controls and so forth could prevent a state-level cyber attacker who could use zero-day exploits even if you do all the basic things right – it is better to have one highly secure layer.
- At small scales, there may be increasing returns, so if you only have 1 FTE researcher to allocate, it may be better to work solely on one layer. Likewise for grantmaking.
- Different defenses may vary greatly in their initial cost-effectiveness. E.g. perhaps the many layers of protection early in the Covid pandemic (masks, social distancing, contact tracing, lockdowns, etc) were less cost-effective than simply investing more resources into accelerating vaccine testing and approval.
- Increased complexity from more layers makes it harder to think cohesively about the entirety of the defenses, increasing the chance that there is a mistake in your safety/security case. Additionally, more components entail more interactions and interference between layers, creating additional surface area for attackers to exploit. E.g. constructing a strong safety for a piece of software may be easier if there are fewer components, even if additional components are ostensibly to improve security.
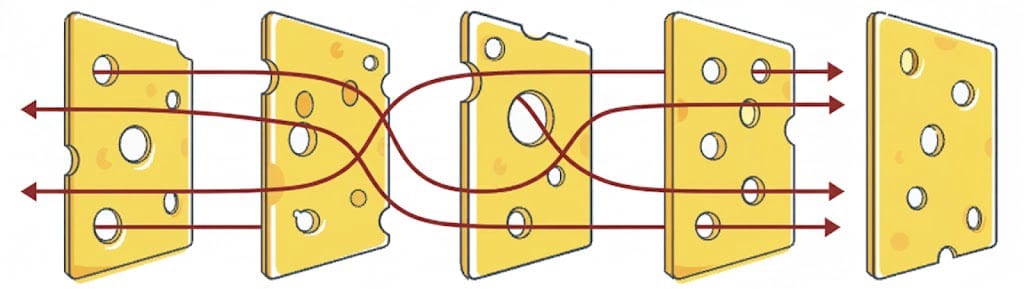
4. Application to AI safety
I think this has a few implications for AI safety:
- Since the adversary in the case of AI threat models will often either be a superhuman AI or a formidable nation state, the point about many weak defenses suffering correlated failures is important here.
- If we can make the layers uncorrelated, or less correlated, these could still be very useful even if each layer only has a small chance of blocking the attack, or imposes modest costs on the attacker.
- Particularly for a safety case that an ASI is aligned, I would far prefer a very strong, relatively straightforward argument that is easy to check all the steps of, rather than many independent but somewhat fuzzy and less strong arguments.
- But of course, such strong arguments are hard to come by, particularly since even if an argument purports to show risks are below some very low level, there is always a chance the argument itself has some unforeseen methodological flaw.
- The point about drawing diverse talent seems important – just focusing on e.g. theoretical computer science would be a big loss.
- Psychologically, a failure mode for the AI safety community could be that the main problem of intent-aligning ASIs just seems so hard that most of us don’t really try, and instead build lots of smaller, less consequential defensive layers. But eventually we do need to solve the main problem (unless we can get weaker AIs to ‘do our homework for us’ - probably this is just the main reasonable plan).
I don’t think there are any specific things I want people to stop/start working on as a result of this. I just think it is useful to remember that DiD is not always the right frame or a strong consideration, and that it is very reliant on defenses being uncorrelated against an intelligent adversary.
—-------
Thanks to Anders Sandber, Christopher Covino, Max Daniel, Mia Taylor, Oliver Guest, and Owen Cotton-Barratt for helpful comments on a draft.
- ^
More generally, one application of DiD to X-risk suggests investing in each of three defensive buckets:
- Preventing catastrophes from starting in the first place.
- Responding in the early stages to prevent escalation to a global catastrophe.
- Resiliency, such that even global catastrophes do not lead to extinction.
- ^
AI image modification still has a ways to go!
An analogy: let's suppose you're trying to stop a tank. You can't just place a line of 6 kids in front of it and call it "defense in depth".
Also, it would be somewhat weird to call it "defense in depth" if most of the protection came from a few layers.
I'm not familiar with how this concept is used in the military, but in safety engineering I've never heard of it as a tradeoff between 'many layers, many holes' vs 'one layer, few holes'. The swiss cheese model is often meant to illustrate the fact that your barriers are often not 100% effective, so even if you think you have a great barrier, you should have more than one of it. From this perspective, the concept of having multiple barriers is straightforwardly good and doesn't imply justifying the use of weaker barriers.
Right, but because we have limited resources, we need to choose whether to invest more in just a few stronger layers, or less each in more different layers. Of course in an ideal world we have heaps of really strong layers, but that may be cost-prohibitive.
Relevant paper from earlier this year that I missed: https://www.far.ai/news/defense-in-depth
I've been confused about the "defense-in-depth" cheese analogy. The analogy works in two dimensions, and we can visualize that constructing multiple barriers with holes will block any path from a point out of a three-dimensional sphere.
(What follows is me trying to think through the mathematics, but I lack most of the knowledge to evaluate it properly.
Johnson-Lindenstrauss may be involved in solving this?(it's not, GPT-5 informs me))But plans in the the real world real world are very high-dimensional, right? So we're imagining a point p (let's say at (0,0,…,0)) in a high-dimensional space (let's say Rn for large n, as an example), and an n-sphere around that point. Our goal is that there is no straight path from p to somewhere outside the sphere. Our possible actions are that we can block off sub-spaces within the sphere, or construct n-dimensional barriers with "holes", inside the sphere, to prevent any such straight paths. Do we know the scaling properties of how many of such barriers we have to create, given such-and-such "moves" with some number of dimensions/porosity?
My purely guessed intuition is that, at least if you're given porous n−1-dimensional "sheets" you can place inside of the n-sphere, that you need ≈exp(n) many of them with increasing dimensionality n.Nevermind, I was confused about this.